
Simple Content Discovery
- Directory brute-force
- Web crawling
- URL archive queries
Complexity: basic
Category: Attack Surface Management
Workflow

Simple Content Discovery
Tools
Setup
To get started, edit the TARGET_DOMAIN string input and add your target domains (e.g. trickest.com) as follows:
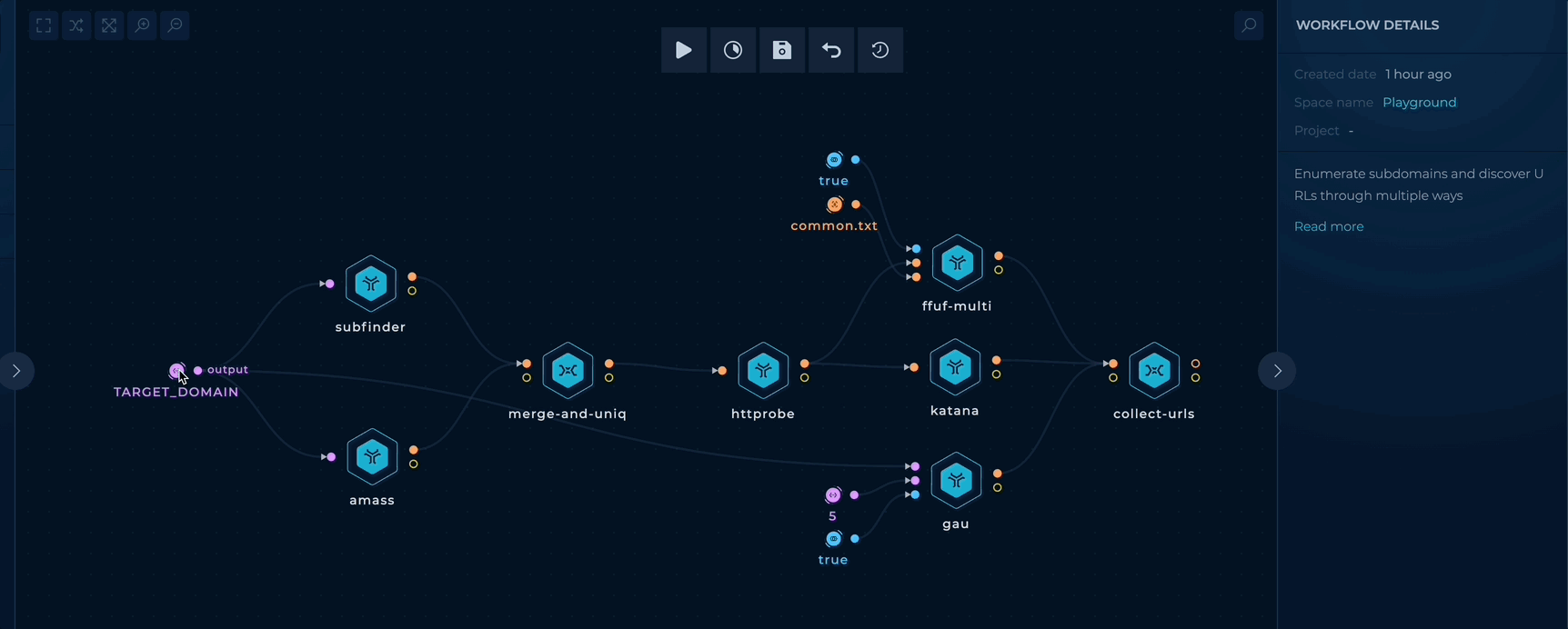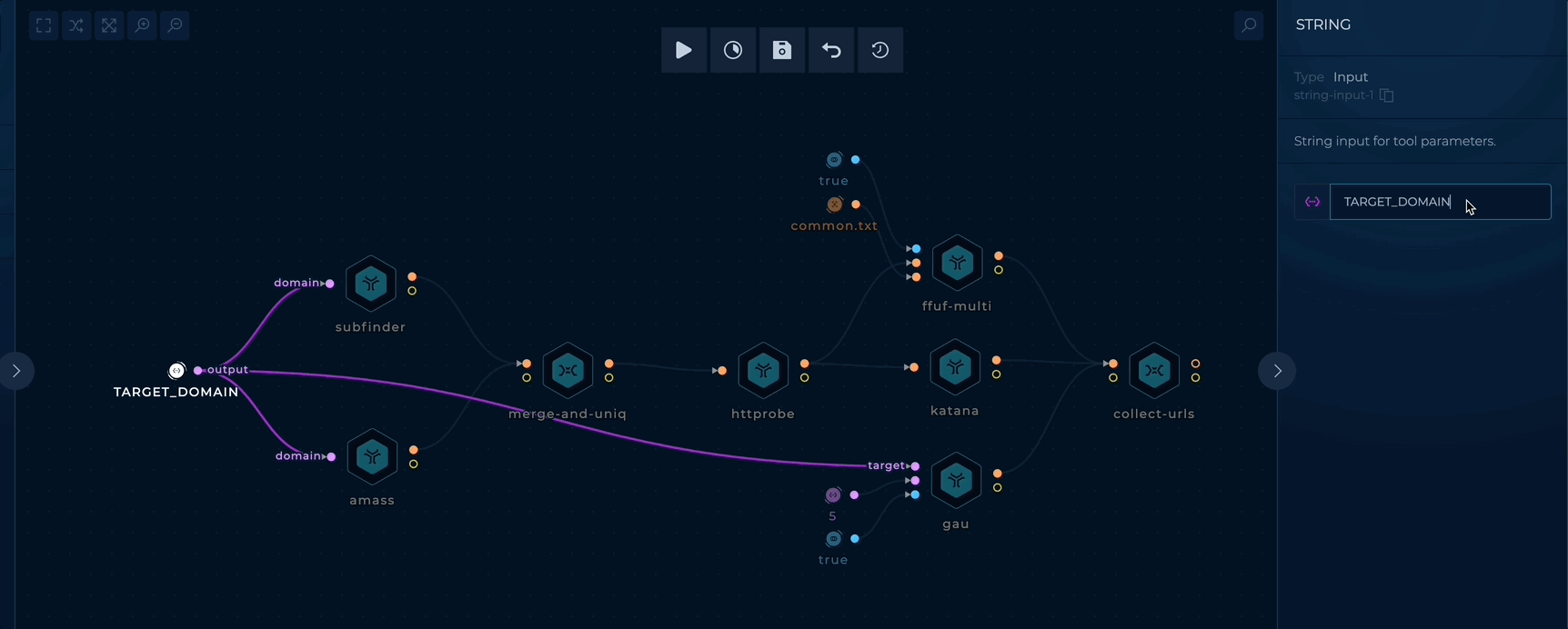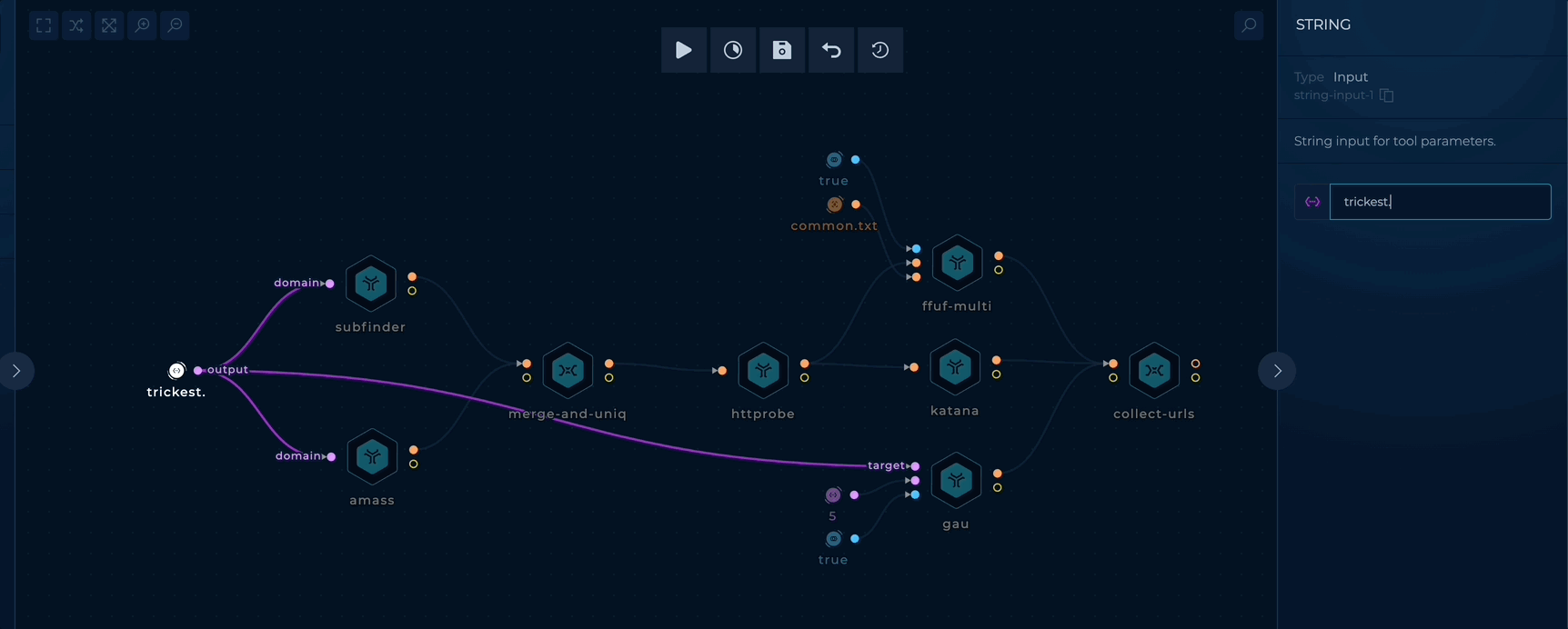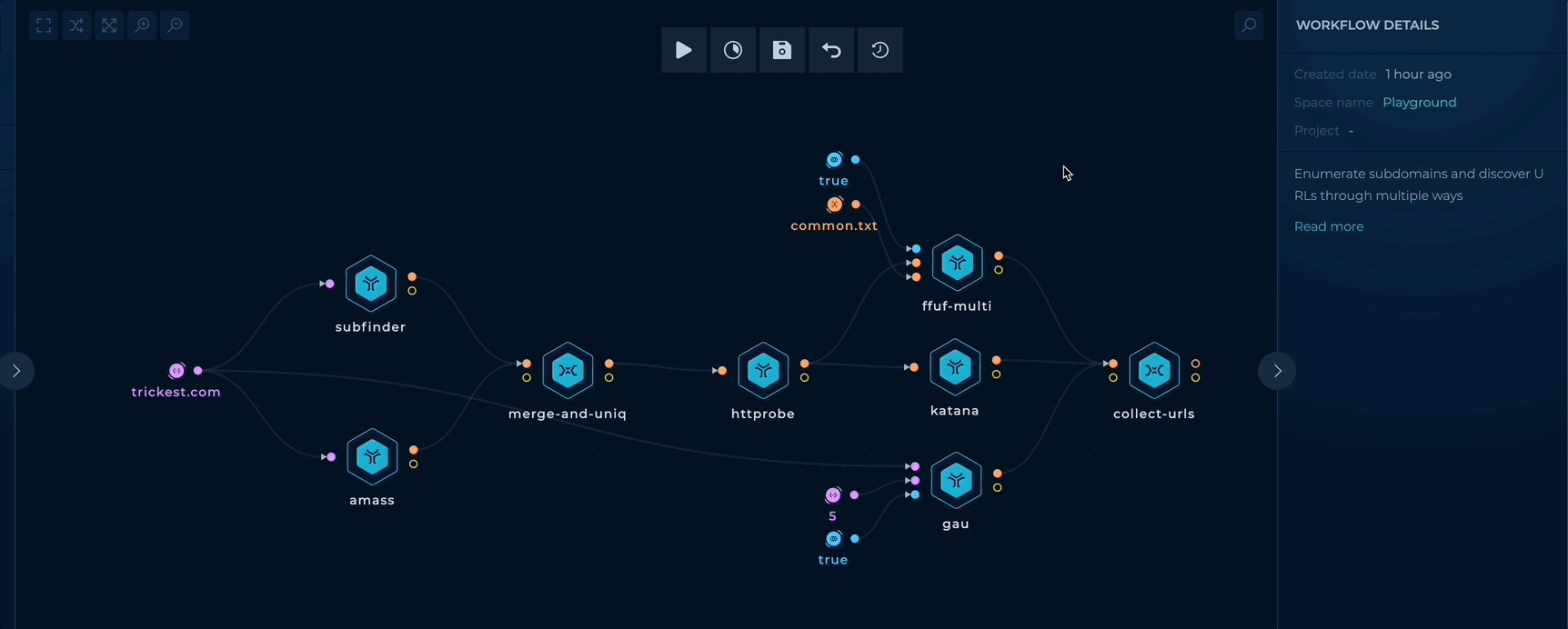
Simple Content Discovery - Setup
Execution and Results
After setting up the workflow, you're ready to hit the execute button to save your changes and run the workflow.
As this workflow has multiple tools that can run in parallel, you can get a faster overall runtime by assigning 2 or 3 machines to the workflow. By default, every tool is configured to run on a small machine but you can change them to make the best use of the resources available to you.
Once the workflow is completed, you can download the output of the collect-urlsnode which will have the deduplicated and merged results of all three content discovery tools as a list of URLs.
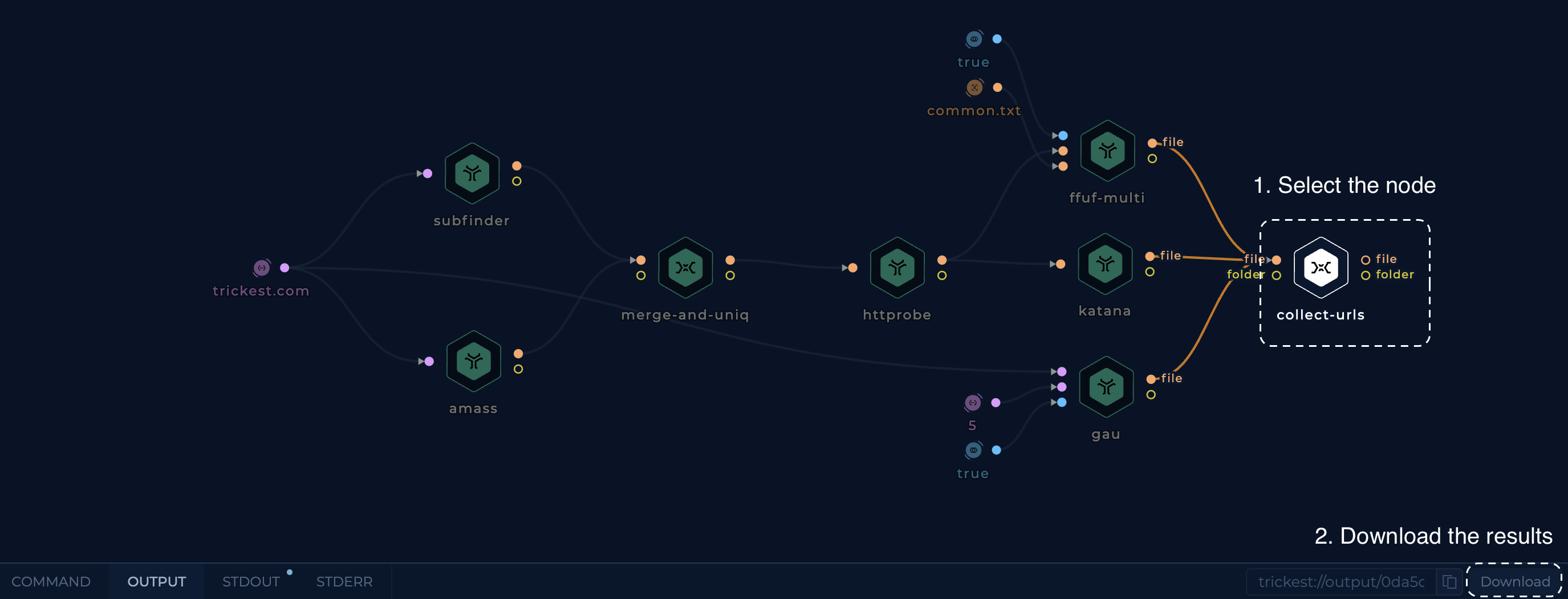
Simple Content Discovery - Results
Try it out!
This workflow is available in the Library, you can copy it and execute it immediately!