
Using Splitters
File-splitter
This is a special kind of node that you can use to loop over a file and execute a series of steps in a workflow on each line, possibly in parallel.
To get started, use your search in Left sidebar to find file-splitter. Connect your file (or tool) to file-splitter ’s multiple input. You will get a string output that you can connect to any other tool. Any tool you connect to file-splitter (including tools further down the chain) will run once for each line in the input file.
In the example below, 2 parallel subfinder instances will run:
subfinder -d trickest.io
And
subfinder -d trickest.com
Trickest file-splitter in action
Tips
- Every tool connected to a
file-splitterusing afileconnection (the orange one), will run separate instances for each line. To collect the outputs of every instance in one node, use afolderconnection (the yellow one) like in the example above. You can use a script likerecursively-cat-allto merge all outputs into one file,zip-to-outto compress the output folder (while maintaining the directory structure) into a zip archive, or write your own custom script. - Assigning more machines to a workflow will allow the
file-splitternodes to run in parallel, resulting in a shorter workflow runtime and faster results. - Currently, there is a 500-line limit on the
file-splitterinput. If you need more iterations, you should consider modifying the workflow structure. It could make more sense to use tools that can process files rather than individual strings. Check out the following section for more details on how to batch-process a file.
Batch-output
You can use file-splitter long with 2 more nodes to create an even more powerful pattern. This pattern allows you to split a file into smaller files (batches) with a specific number of lines in each batch, then pass these batches to the following nodes concurrently.
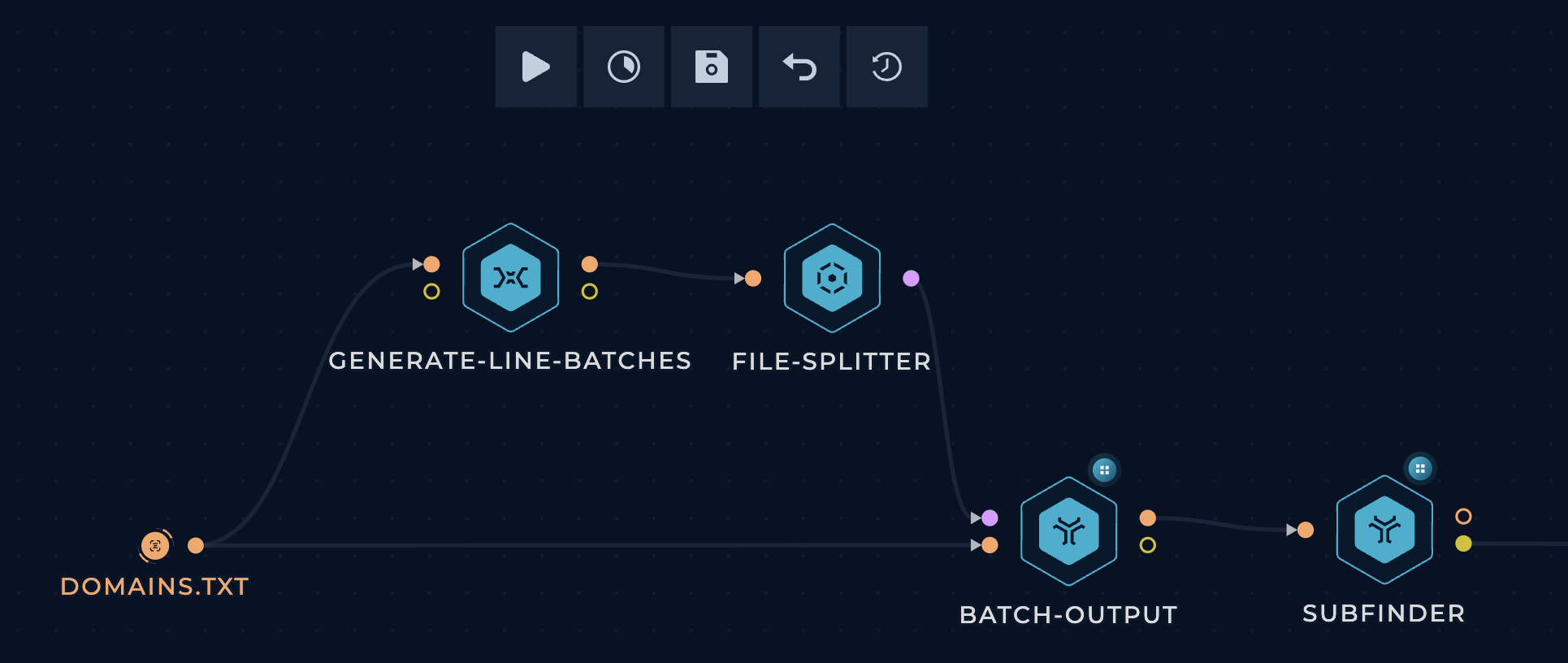
Trickest batch-output
Start by dragging the required nodes (generate-line-batches, file-splitter, and batch-output) from the Left sidebar and connect them as shown in the image, and connect them to your desired tool.
The way this works is as follows:
generate-line-batchescalculates line ranges based on the number of lines in the file and the specified batch size.file-splitterpasses the line ranges one by one tobatch-output.batch-outputextracts the specified line range from the file into a batch and passes each batch concurrently to the following nodes.
Tips
- The default batch size is 100 lines. If you want to change it, edit the
BATCH_SIZEvariable at the top of thegenerate-line-batchesscript. - All the file-splitter tips apply here as well. Give them a read!