
Alexa's Top 1000 robots.txt
Complexity: basic
Category: Utilities
Repository: https://github.com/trickest/wordlists
Tools
Setup
This workflow doesn't need any additional setup. You can copy it from the Library and execute it!
Build in steps
Getting the Alexa's CSV file with custom-script and parsing it
We can use a simple script that will download CSV from an external resource and parse it to get the most popular root domains worldwide.
wget -q http://s3.amazonaws.com/alexa-static/top-1m.csv.zip
unzip top-1m.csv.zip
awk -F ',' '{print $2}' top-1m.csv | head -1000 > out/output.txt; rm top-1m.csv*
We can accomplish that by drag&droping custom-script node and pasting the bash script above.
Notice the `out/output.txt` path, this path is used for `file` output ports.

Get Alexa's CSV parse it and output root domains
Using sed to append protocol with sed-add-to-beginning
We can use a simple script to append https:// to each of the lines gathered in the previous step. This will create a list of webservers that we will use to get the robots.txt files.

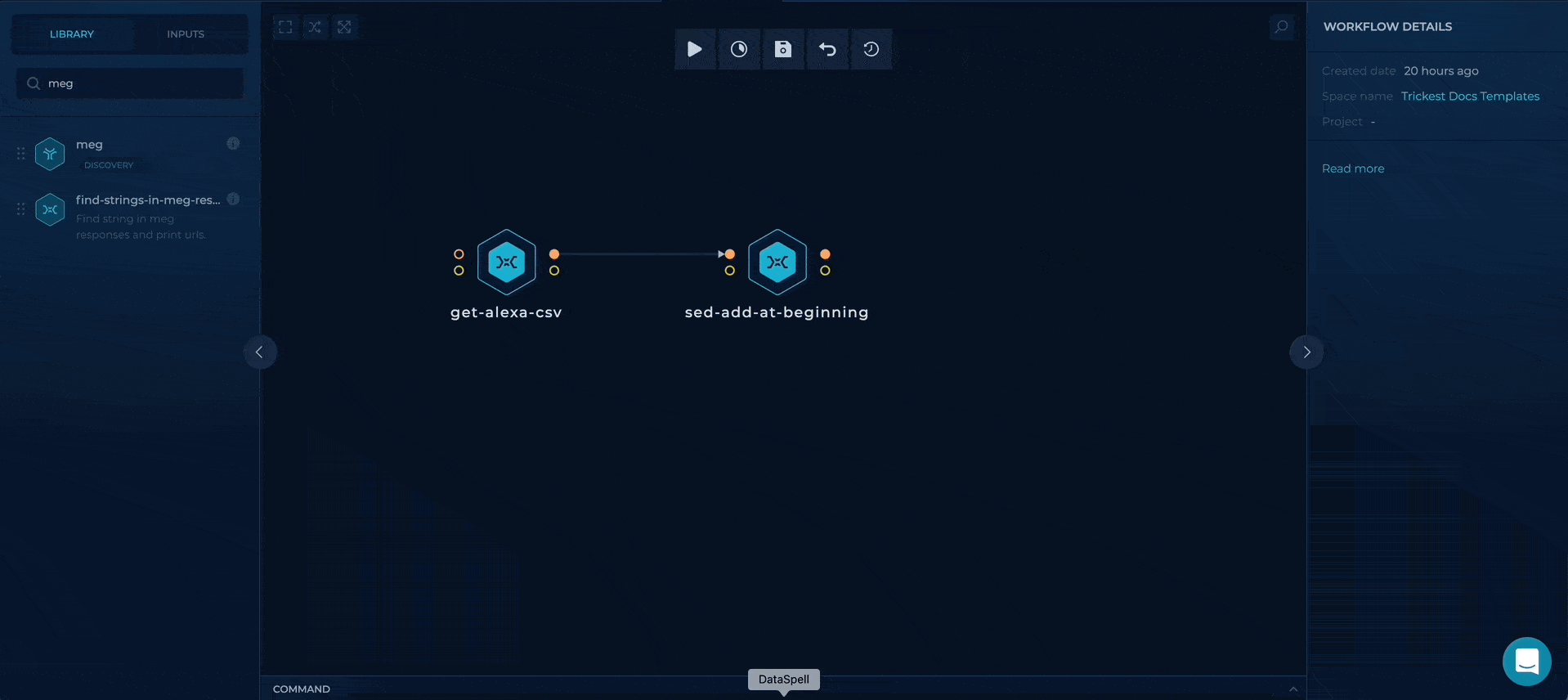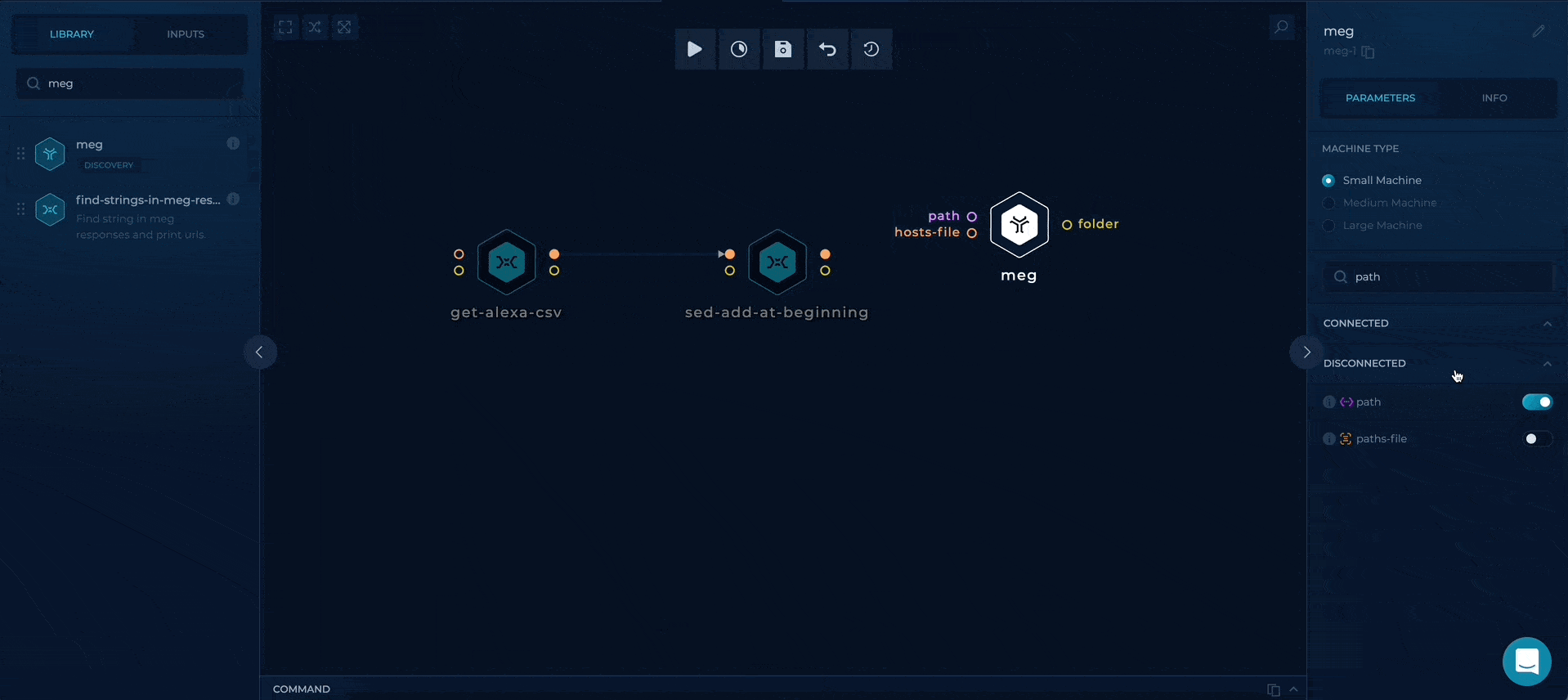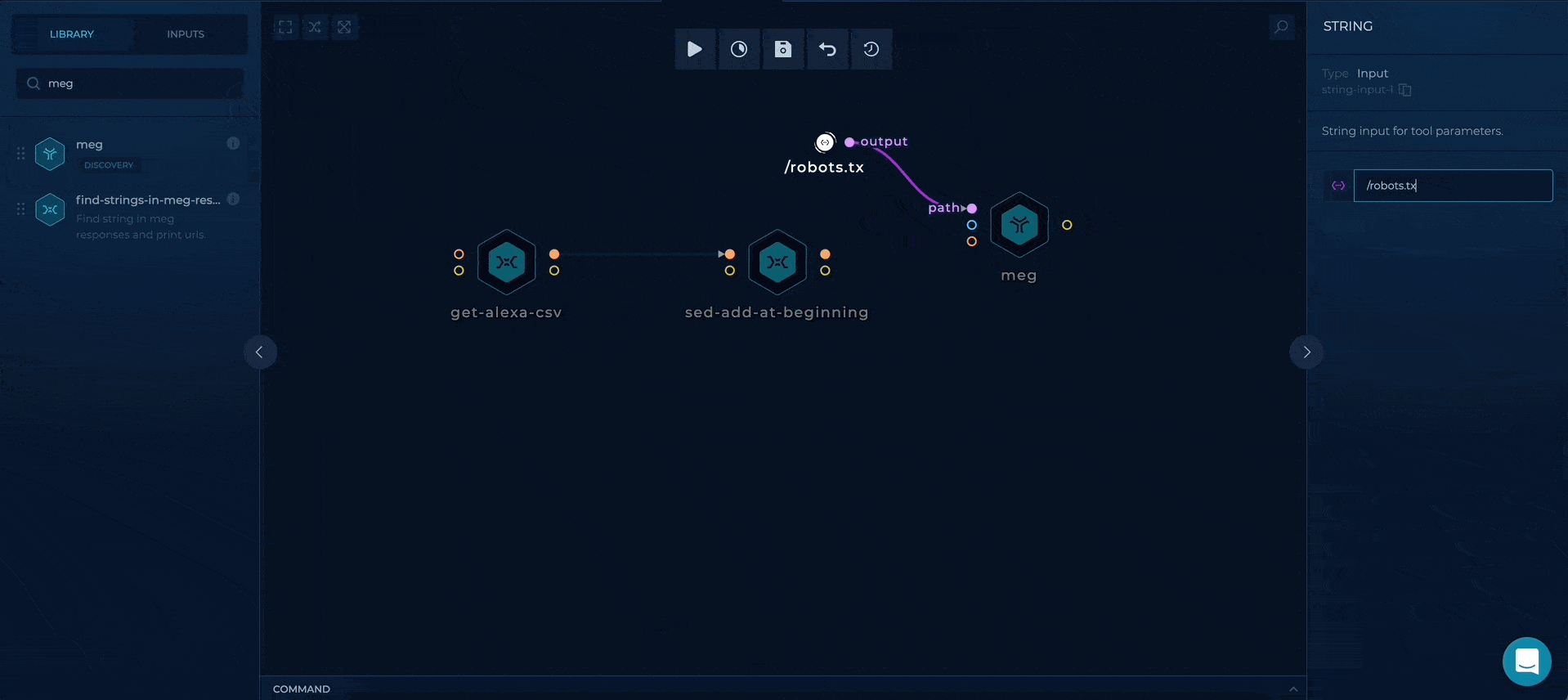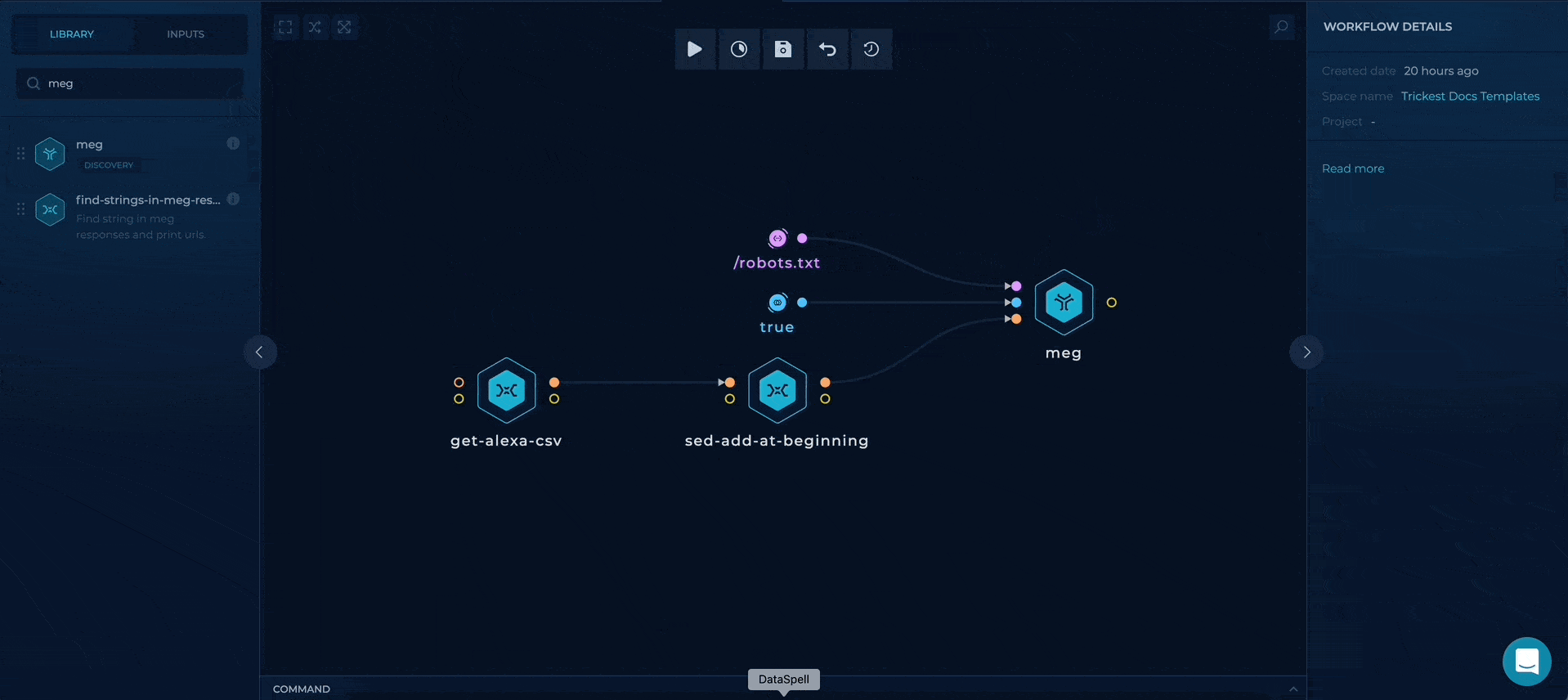
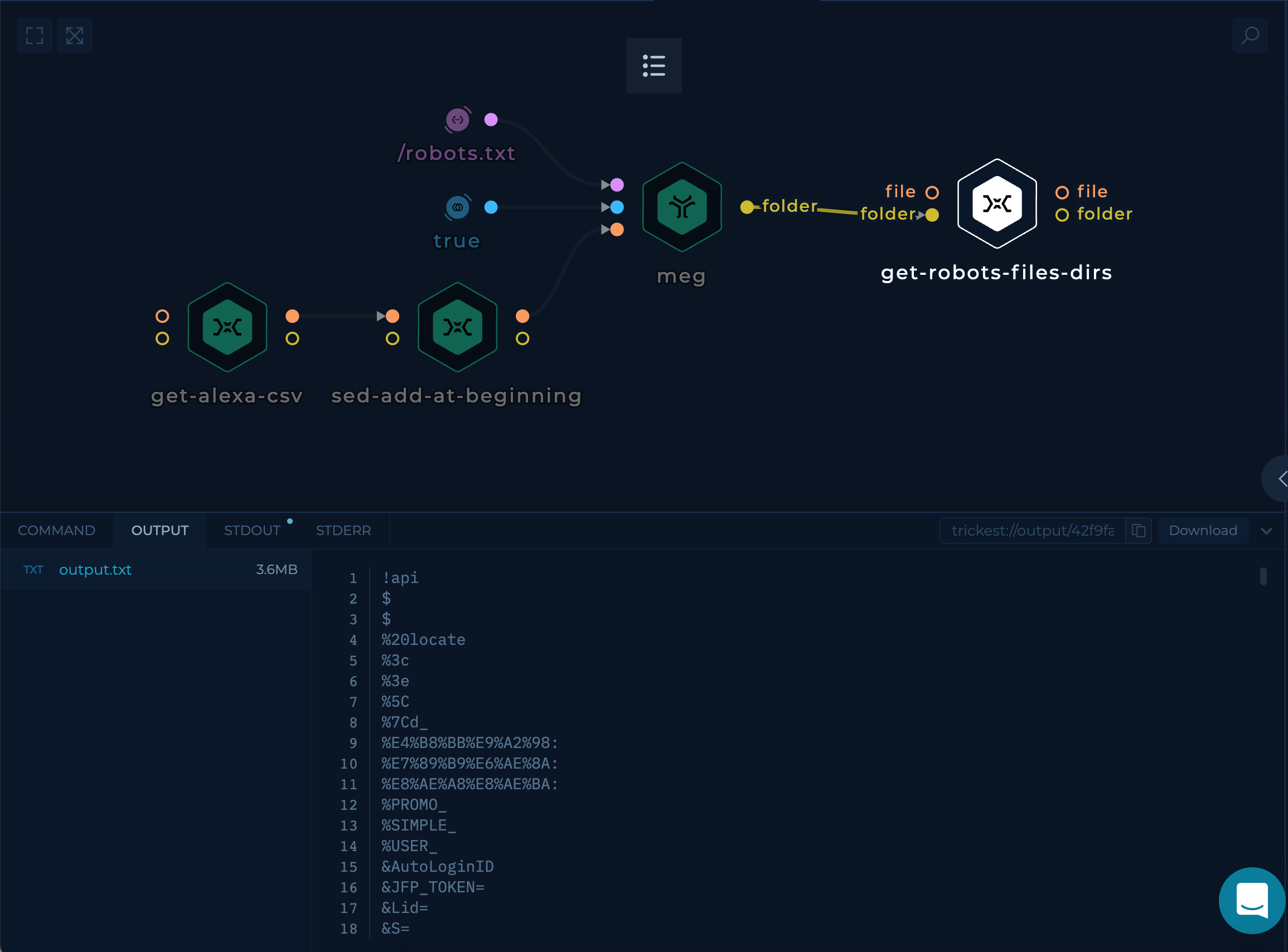
Using meg to get the responses
We can use meg to gather all of the HTTP responses containing content of our robots.txt files. This can be accomplished by providing a path parameter to meg, with additional follow-redirects which will continue sending requests on 30x responses.
Parsing robots.txt responses with custom-script
Meg will output all of the responses into a folder, which could be consumed by connecting folder output to another custom-script node.
Here is the code that successfully parses all the responses and creates a wordlist at the end, which could be downloaded and used either locally or in another workflow.
find in/ -mindepth 3 -type f -exec cat {} + | egrep -w "Disallow|Allow: " | awk '{print $2}' | sed 's/^\///' | sed 's/\/$//' | sed '/^[[:space:]]*$/d'| sed 's/\*$//' | sed 's/^\*//' | sed 's/\/$//' | sort -n | uniq > out/output.txt
This script will search all the files available inside in folder, and use a couple of egrep and sed commands to extract the paths ant put it into out/output.txt
Execution and results
get-robots-files-dir will contain the latest results of the workflow execution.
Try it out!
This workflow is available in the Library, you can copy it and execute it immediately!
Improve this workflow
- Changing machine type of tools to speed up the execution
- Customizing the
get-alexa-csvscript to gather more root domains - Executing the script on schedule and using get-trickest-output to be able to save all previous executions
- Adding webservers and tools like ffuf to brute-force files and folders with the newly created wordlist
Explore other Utilities workflows from Trickest library!