Parsing more than 10TB of GitHub Logs with Trickest and Extracting Public Details of all GitHub Users & Repositories
Learn how you can use Trickest workflow methodology to parse around 15TB of GitHub logs and extract public details from all discovered users and repositories.

Carlos Polop
Cloud Pentesting Team Leader
In today's digital age, the massive expanse of data available to us offers incredible opportunities yet also presents complex challenges. Among these challenges is the task of navigating and parsing vast data logs, especially when dealing with open-source platforms like GitHub. This blog post will dive into how I employed Trickest's workflow methodology to parse over 10TB of GitHub logs, extracting public details from all the users and repositories present, turning a colossal data pool into useful insights.
Understanding the importance of this topic is crucial, as GitHub embodies a vibrant, ever-evolving ecosystem of developers and their projects. Through parsing this data, we have the opportunity to gain insights that could otherwise slip under the radar, generating a wealth of open-source intelligence (OSINT), which can enhance user engagement, address targeted problem-solving, and foster predictive analytics.
Using the recent Trickest engine update, which boosts node performance and reliability, I embarked on a journey to parse all the GitHub logs from 2015, extracting the public information for all users and repositories logged within. This exhaustive process allowed me to generate a comprehensive list of all users and repositories spanning from 2015 up to now.
Despite GitHub's limited OSINT data, my goal was to bolster the community's knowledge by sharing our findings and offering additional details derived from the GitHub API about the users and repositories logged.
Exploring the GitHub Archive
While there aren't publicly available rankings of repositories sorted by star or fork counts, user contribution records, or even the identities of deleted users, the GH Archive steps in to fill this gap. This valuable resource houses all GitHub logs from 2011 onwards, a testament to GitHub's dedication to community service.
These logs contain valuable information, including details about changes made to each repository, as well as the individuals behind these changes. Parsing this data allows for the uncovering of all users and repositories - created, deleted, altered, and beyond. This abundance of information can be harnessed for OSINT purposes.
However, it's essential to remember the sheer scale of the archive. With approximately 15TB of logs (even when compressed to save space), parsing this volume of data is certainly a significant undertaking.
Parsing the Logs
For the initial step, I turned to the recently upgraded Trickest engine to manage this data, attracted by its capability for running tasks in parallel and its remarkable speed. To streamline the process, I chose to limit execution to medium machines (4GB of RAM) running in parallel. Given the substantial volume of data, these machines needed to parse, it was critical to keep the scripts as memory-efficient as possible for parsing all the logs.
We chose to parse logs from 2015 onward, as it was from this point that the logs were officially recorded via the Events API.
The task of parsing presented its own set of challenges, given the vast quantity of data to parse and store. This required several iterations to determine the most efficient strategy for downloading, parsing, and storing the data for future analysis. The process was so demanding that Trickest had to ramp up the volume sizes to hold all the data. Consequently, the initial script, designed for downloading and parsing the data, was divided into three distinct stages:
-
The first stage was devoted to generating all necessary URLs for downloading the logs. The URL format was
{year}-{month:02d}-{day:02d}-{hour:02d}.json.gz. We configured Trickest to handle these URLs in parallel chunks of 200. -
The second stage involved the script gh-scraper, which took in several log URLs as input, downloaded, and parsed each individually. For handling large downloads, we used the script
curlas it proved more efficient than the Python requests library. To parse the data, the script opened each file as a JSON, pulled the necessary information (names of users, repositories, and records of changes in each repository), and wrote this data into a CSV file. The program downloaded, parsed, and wrote files sequentially before proceeding to the next file. This approach was designed to minimize memory usage. -
The final stage involved custom Python scripts that read all the CSV files generated earlier, merged them, combined results, and removed duplicates. We developed separate scripts for extracting both user and repository information.
The image below provides a visual representation of how the workflow appeared:
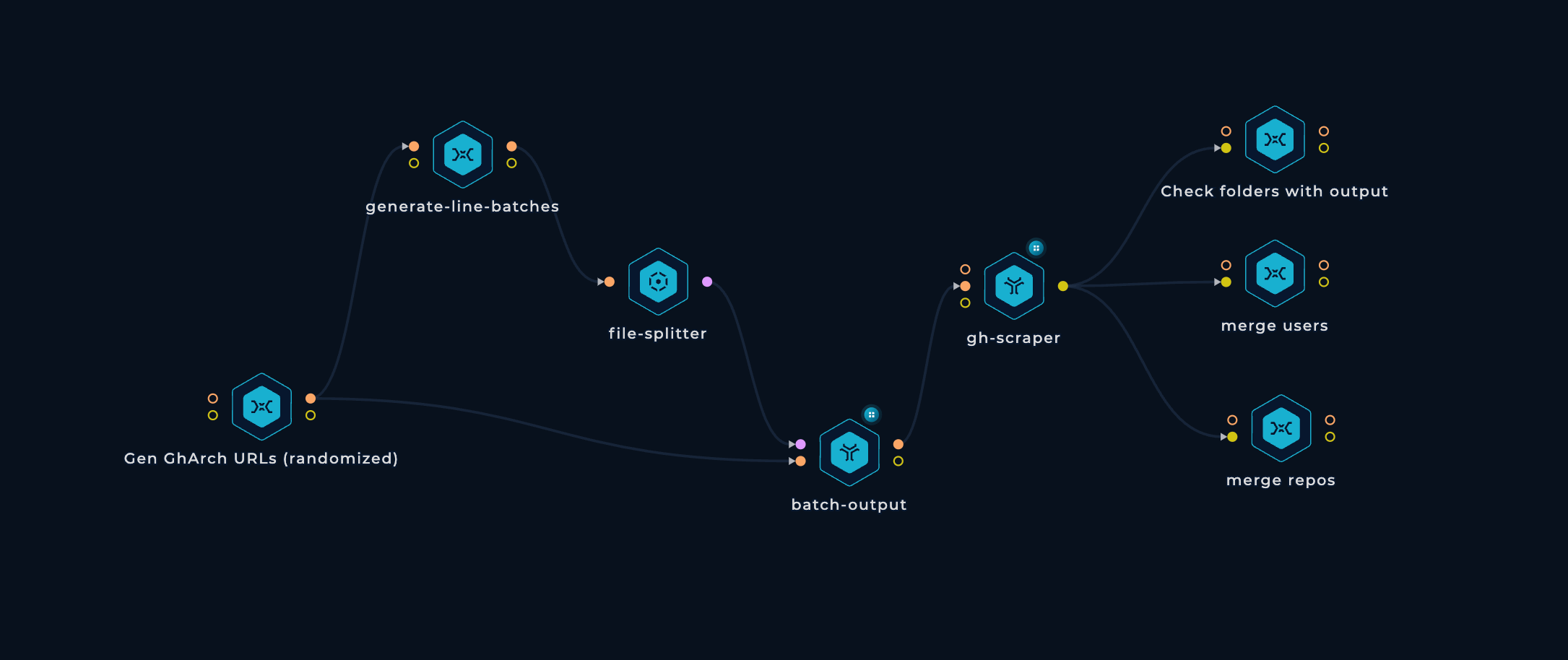
Despite the fact that these scripts are highly memory-efficient, the code may not appear elegant due to several modifications made to handle this volume of data on machines with just 4GB of RAM.
Running the Workflow
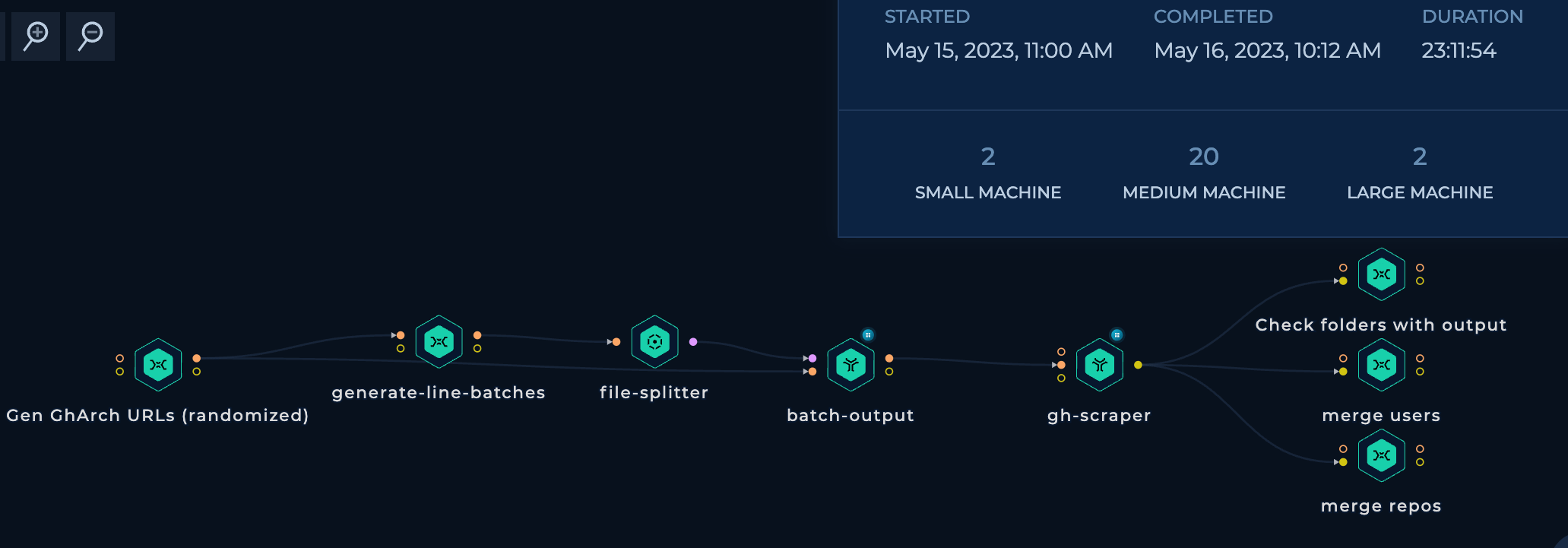
Upon initiating the workflow, it took slightly over 23 hours to download, parse, and merge all the data. The merging process itself occupied 19 hours on two parallel large machines, one each for users and repositories. The downloading and parsing utilized 15 parallel medium machines, consuming a mere 4 hours to download, decompress, and parse all the GitHub logs. A special acknowledgment goes to Trickest for managing such a massive dataset with such speed.
The result was a sizable 4.6GB CSV file containing data on more than 45 million users and the repositories they had contributed to. Additionally, an 8.6GB CSV file containing data on more than 220 million repositories.
Enhancing the Data
Despite having a list of users and repositories that had been created, deleted, modified, etc., from 2015 to the present day, detailed information was missing. To resolve this, we decided to enrich the data with the GitHub API.
We created two similar workflows in Trickest to enhance the CSV files created in the previous step with the GitHub API:
- The workflow began by downloading the CSV file that listed either users or repositories.
- The list was then divided into chunks of 1,000,000 users or repositories to ensure efficient parallel processing without overloading a medium machine.
- I ran the script gh-enhancer to enrich each segment of users and repositories using the GitHub API.
- The enhanced data from all segments was merged into a single CSV file.
- Finally, we used the script gh-investigator to extract interesting information from the CSV file generated in the previous step.
"Enhance Users" Workflow
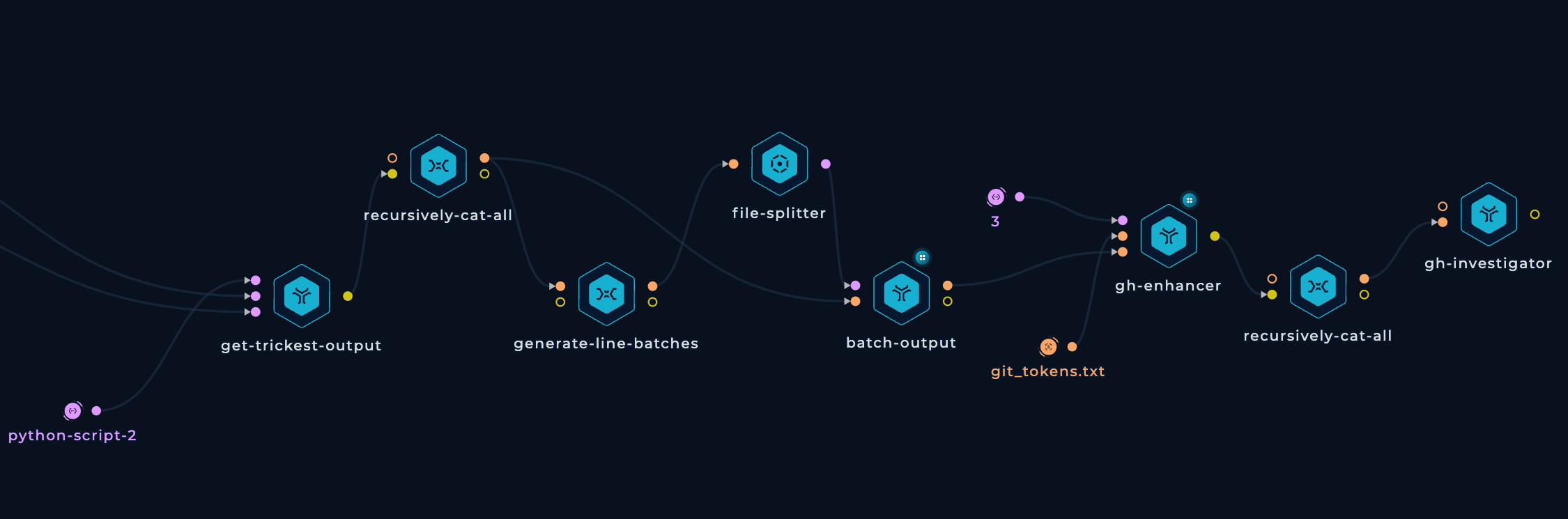
Executing the workflow on 4 medium machines in parallel took roughly 11 hours and 45 minutes. To avoid exceeding the request per hour limit, I utilized 5 different GitHub API keys. However, I never reached the API rate limit, suggesting that the process could have been completed faster by using more machines in parallel.
The final user CSV file was 4.6GB and contained details of approximately 45 million users, such as:
user,repos_collab,deleted,site_admin,hireable,email,company,github_star
carlospolop,"carlospolop-forks/PEASS-ng,carlospolop/TestAWSOpenID,carlospolop/aws-Perms2ManagedPolicies,carlospolop/winPE,carlospolop/Auto_Wordlists,carlospolop/hacktricks-cloud,CyberCamp17-MupadmexCrew/maltrail,...",0,0,0,,,0
[...]
The gh-investigator script created files with the following information:
- List of users who are
site_admin - List of users who are
hireable - List of users who have configured a public
email - List of users who have configured a
company - List of users who are
github_star - List of users who have
deletedtheir account
"Enhance Repos" Workflow:

This workflow took over 32 hours to run on 15 medium machines in parallel. We used the same 5 different GitHub API keys, and in this case, we did hit the API rate limit.
The final repository CSV file was 8.8GB and contained details of over 220 million repositories, like:
full_name,stars,forks,watchers,deleted,private,archived,disabled
carlospolop/PEASS-ng,12368,2634,220,0,0,0,0
[...]
The gh-investigator script created files with the following information:
- List of repositories sorted by
stars(only those with more than 500 stars) - List of repositories sorted by
forks(only those with more than 100 forks) - List of repositories sorted by
watchers(only those with more than 30 watchers) - List of
deletedrepositories - List of
privaterepositories - List of
archivedrepositories - List of
disabledrepositories
In Conclusion
We succeeded in our goal of parsing approximately 15TB of GitHub logs dating back to 2015, all within a span of 23 hours and 45 minutes, and further enriched this data using the GitHub API. This project led to the creation of a comprehensive database of all users and repositories, those created, deleted, modified, and more, spanning from 2015 to the present, complete with detailed insights on each.
For those intrigued by our process and looking to build their own workflows, or perhaps utilize pre-existing ones, we invite you to sign up and start your own journey, absolutely free. In the upcoming installment of this blog series, we're excited to delve deeper into the data analysis, share our discoveries, and provide access to all the GitHub data we've collected.
Get a PERSONALIZED DEMO
See Trickest
in Action
Gain visibility, elite security, and complete coverage with Trickest Platform and Solutions.