loading
Loading content
loading
Cloudflare bypass technique that scans every AWS IP range to discover the origin IP of web servers hidden behind Cloudflare, Incapsula, or Sucuri.

Carlos Polop · Cloud Pentesting Team Leader
In order to improve the security of web pages, companies use proxy services from providers such as Cloudflare, Incapsula, Sucuri, Akamai, etc. Web applications are allocated behind the mentioned proxies, so the public can only interact with them through these proxies, which are applying security measures. However, these web applications are usually going to be running on a server with an IP address. Therefore, if a pentester manages to find the origin IP address hosting the web application, he or she could be able to access to web application directly in that IP, bypassing all the protections of the proxies.
According to Statista, in 2022, 64% of the Internet was running in the 3 main cloud providers, and 38% in AWS alone. Therefore, there are good chances that the IP running the web application behind a proxy is going to be running inside a cloud provider.
This blog post is going to cover a search for the origin IP address of a web page by scanning all the IP addresses belonging to AWS and checking each using the Trickest workflow automation.
Let's start with the web page http://cloudflare.malwareworld.com/ and put it behind Cloudflare.
This is what it looks like:
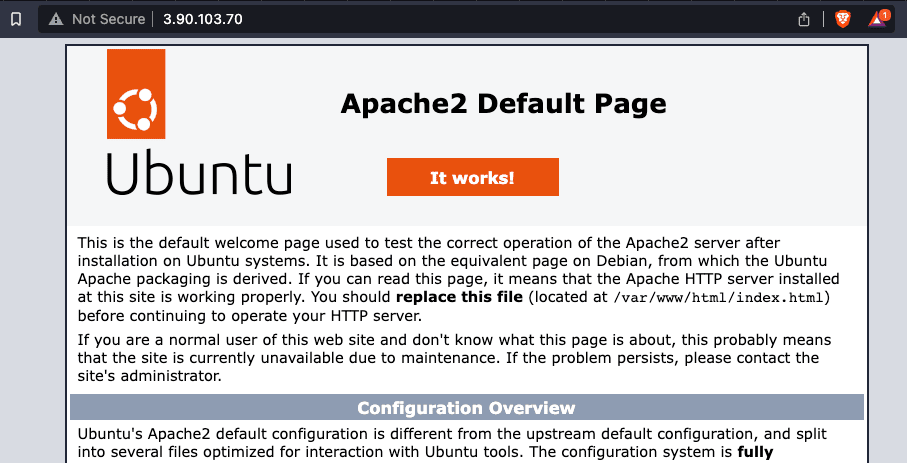
The web is running in an EC2 instance with the IP 3.90.103.70, but if I check the "A" DNS record, I get an IP inside Cloudflare's network:
dig cloudflare.malwareworld.com
; <<>> DiG 9.18.1-1ubuntu1.2-Ubuntu <<>> cloudflare.malwareworld.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16132
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 65494
;; QUESTION SECTION:
;cloudflare.malwareworld.com. IN A
;; ANSWER SECTION:
cloudflare.malwareworld.com. 300 IN A 104.21.58.225
cloudflare.malwareworld.com. 300 IN A 172.67.209.86Therefore, a pentester won't know on which IP this web page is running.
Moreover, if someone accesses the web page through the IP directly, this is what he or she will find:
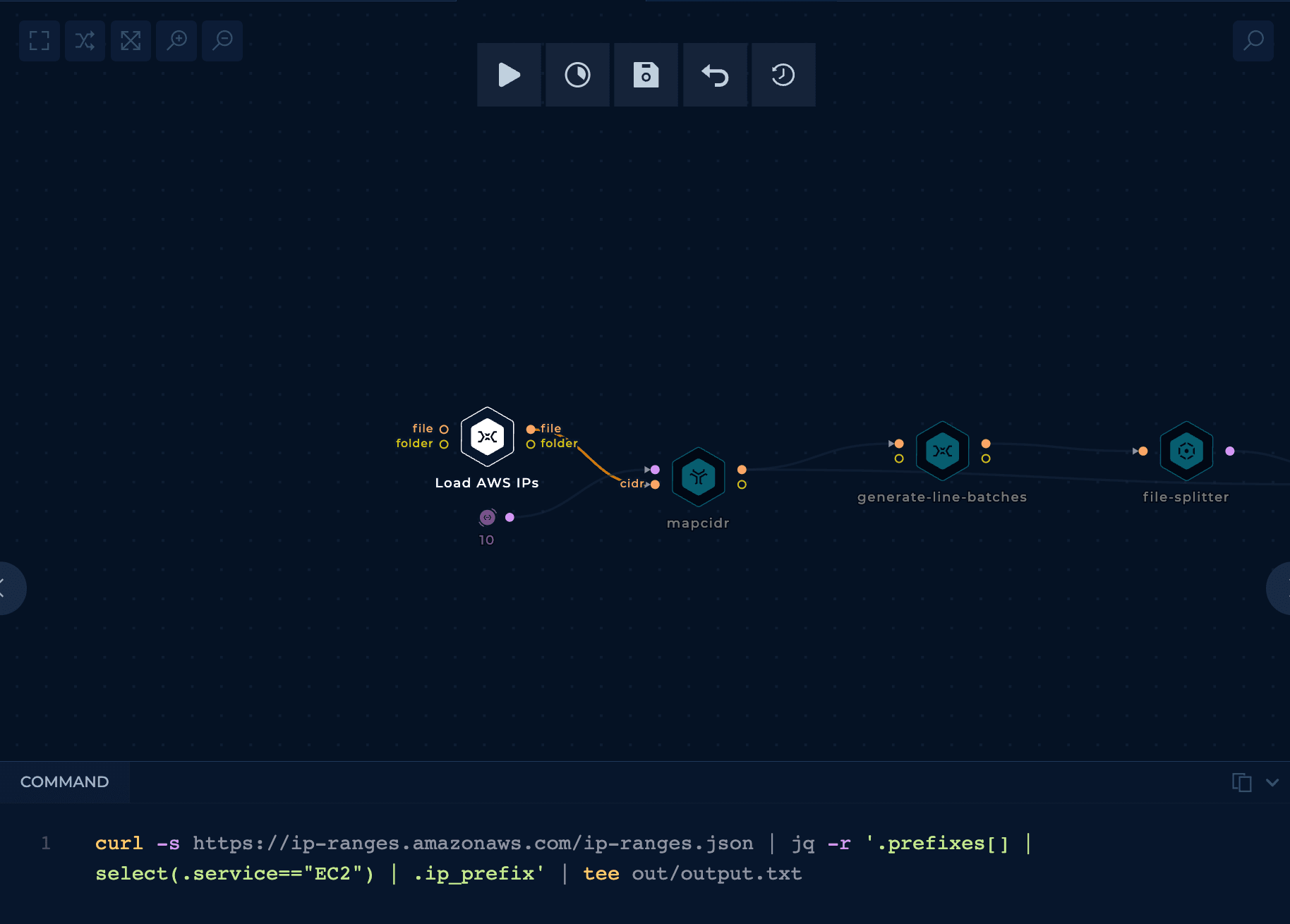
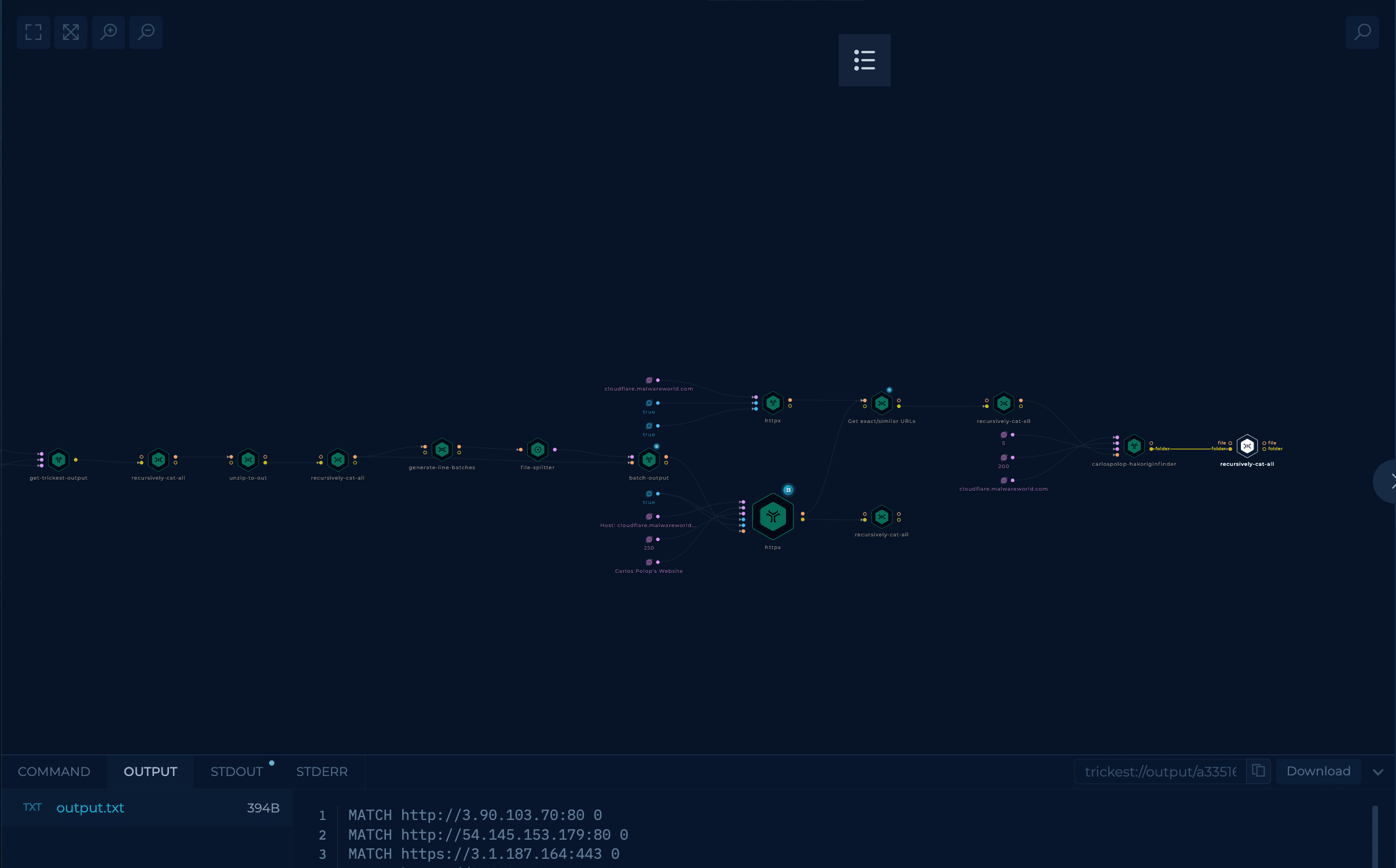
Let's start by creating a workflow to discover all the web applications in ports 80 and 443 in IPs that belong to AWS.
Only ports 80 and 443 are going to be checked because those are the used ports when hiding things behind Cloudflare.
The initial node is connected to a mapcidr node that will reduce too big ranges to smaller ranges because rustscan had some trouble managing big ranges. This is done with a python script.
rustscan in parallelThe initial part of the workflow is to use parallelize the use of rustscan.
The BATCH_SIZE used in the node generate-line-batches is 50000. It's a value that I found that won't overload rustscan with too many IP addresses (as it will be running on a medium size machine).
If you don't understand this part of the work check out the Trickest docs as a guideline.
The parameters used with rustscan are:
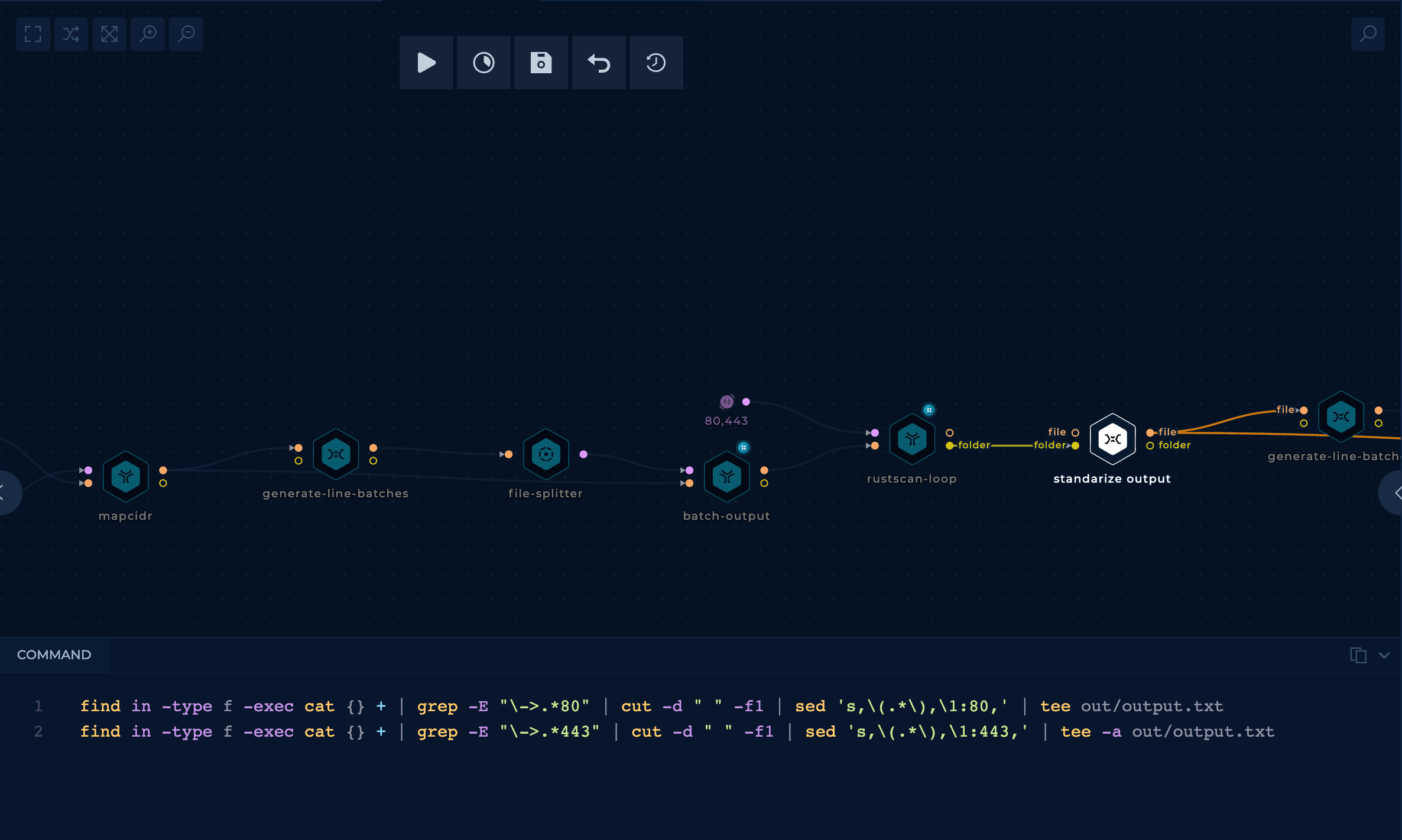
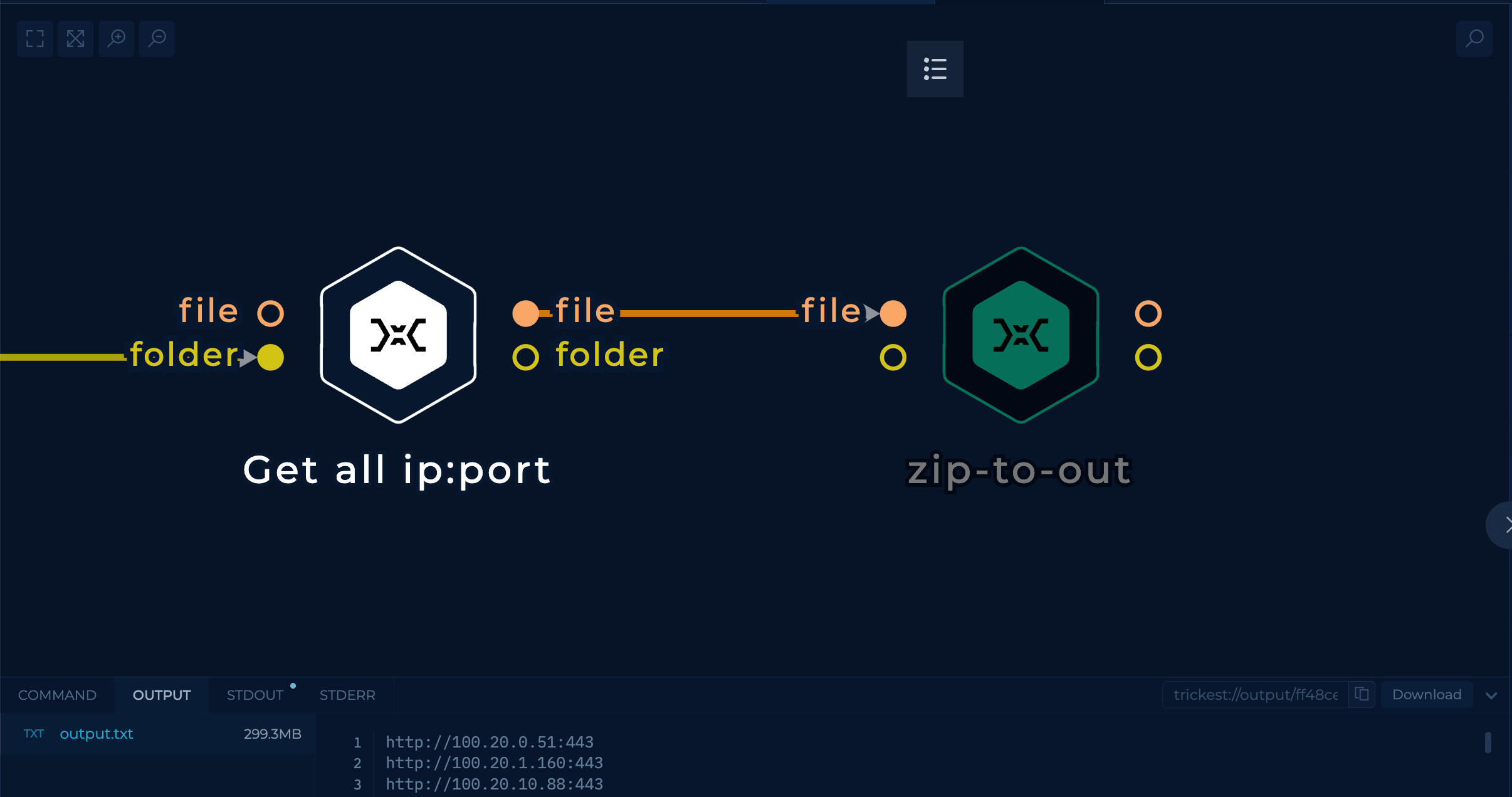
Then, from the rustscan output, get a nice list in the format <IP>:<PORT> using the standardized output node (a custom shell script).
Note that I used rustscan instead of masscan, because, even if masscan could be faster, in my tests, it had too many false negatives (open ports weren't found open).
The tool httpx can be used to confirm that the open ports are web servers.
This task is again done in parallel with a BATCH_SIZE of 55000 in this case.
The parameters used with httpx are:
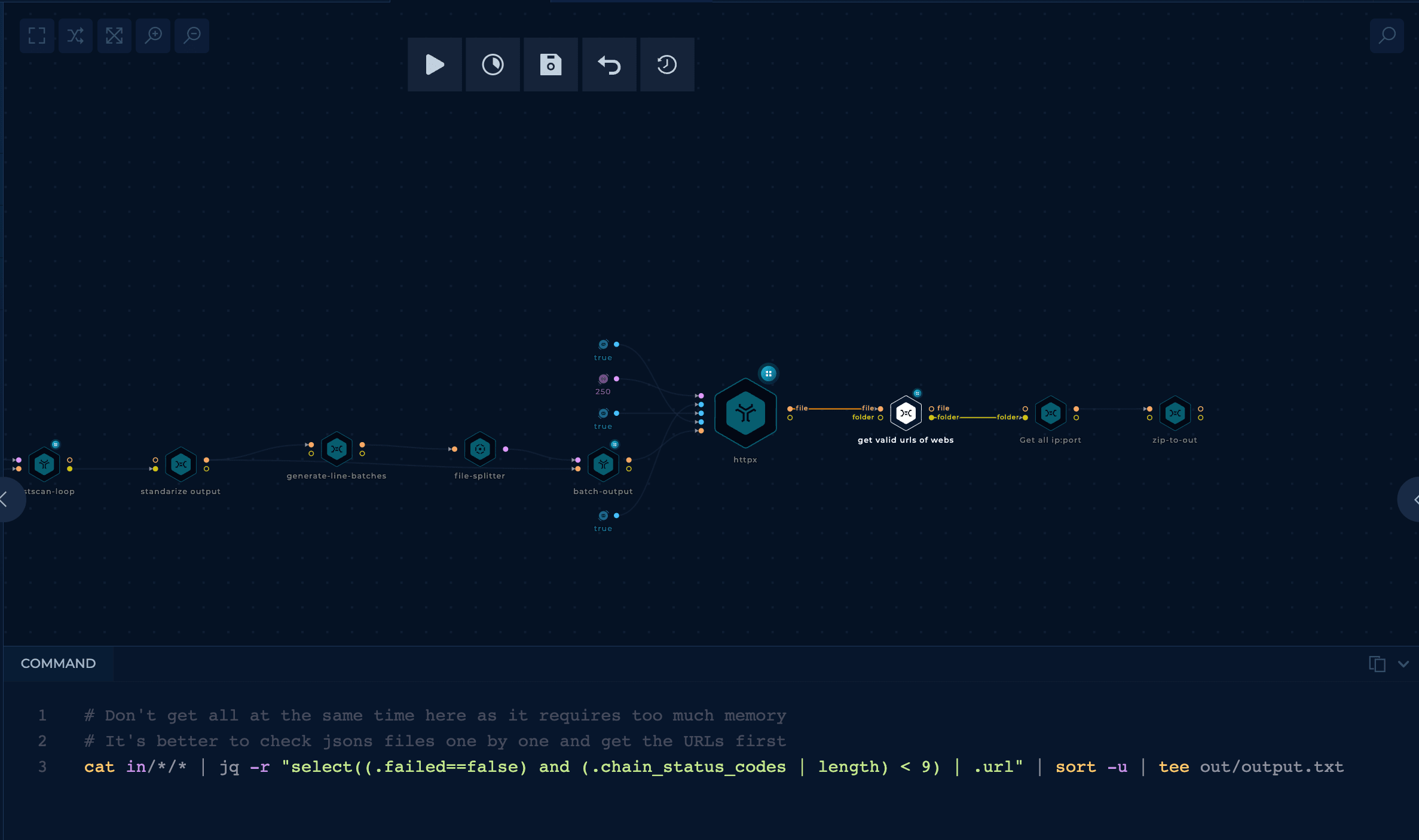
<IP>:<PORT> to checkThe code seen in the image is from the node get valid urls of webs, which will get the valid URLs from the output of httpx. Some URLs answer with eternal redirects, and we are also removing those in this node.
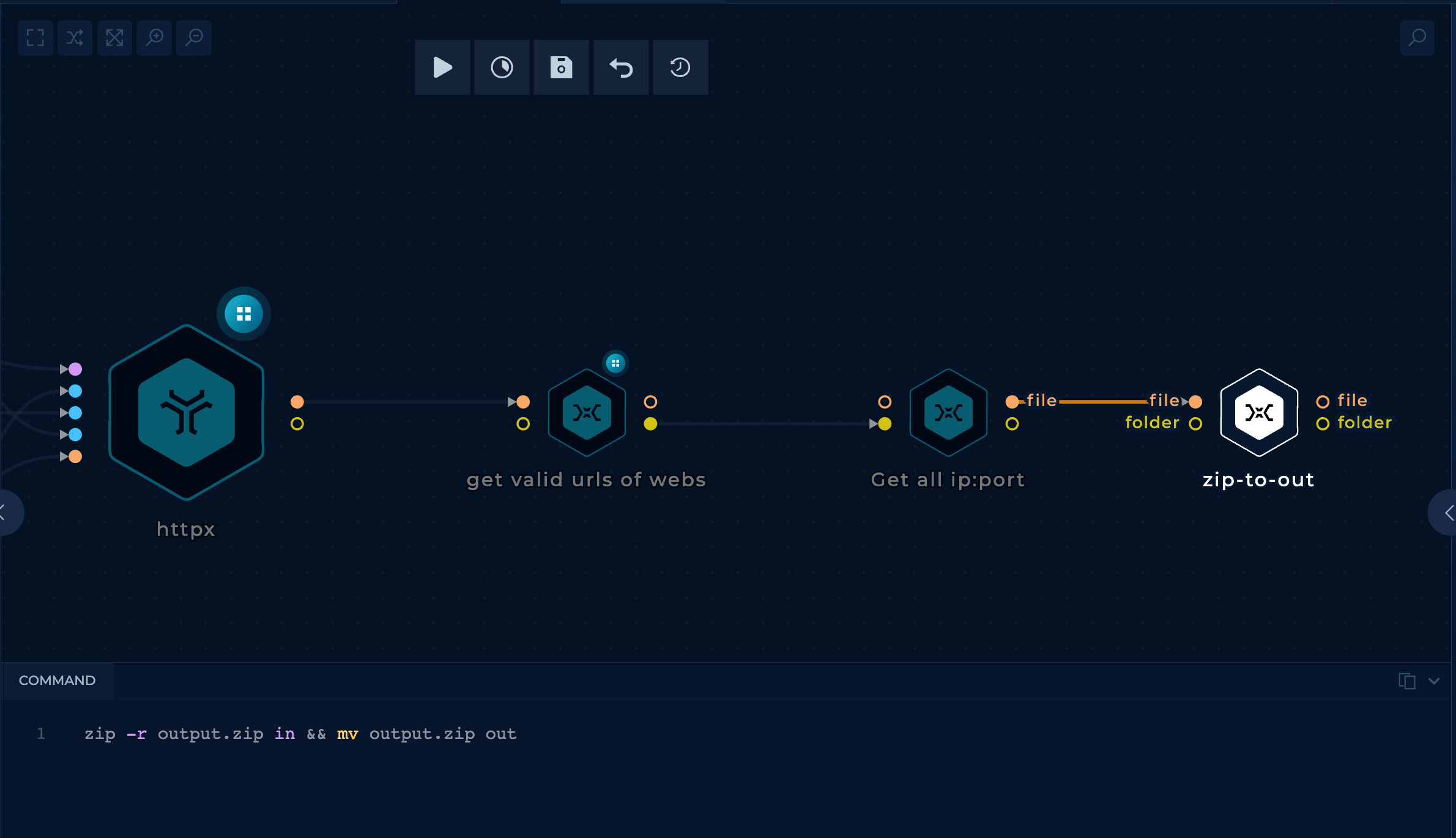
The last step is to get all the valid URLs in a list and zip that list.
One Trickest run with 3 medium machines took close to 20 hours to complete and found almost 13 million URLs (35MB zip file).
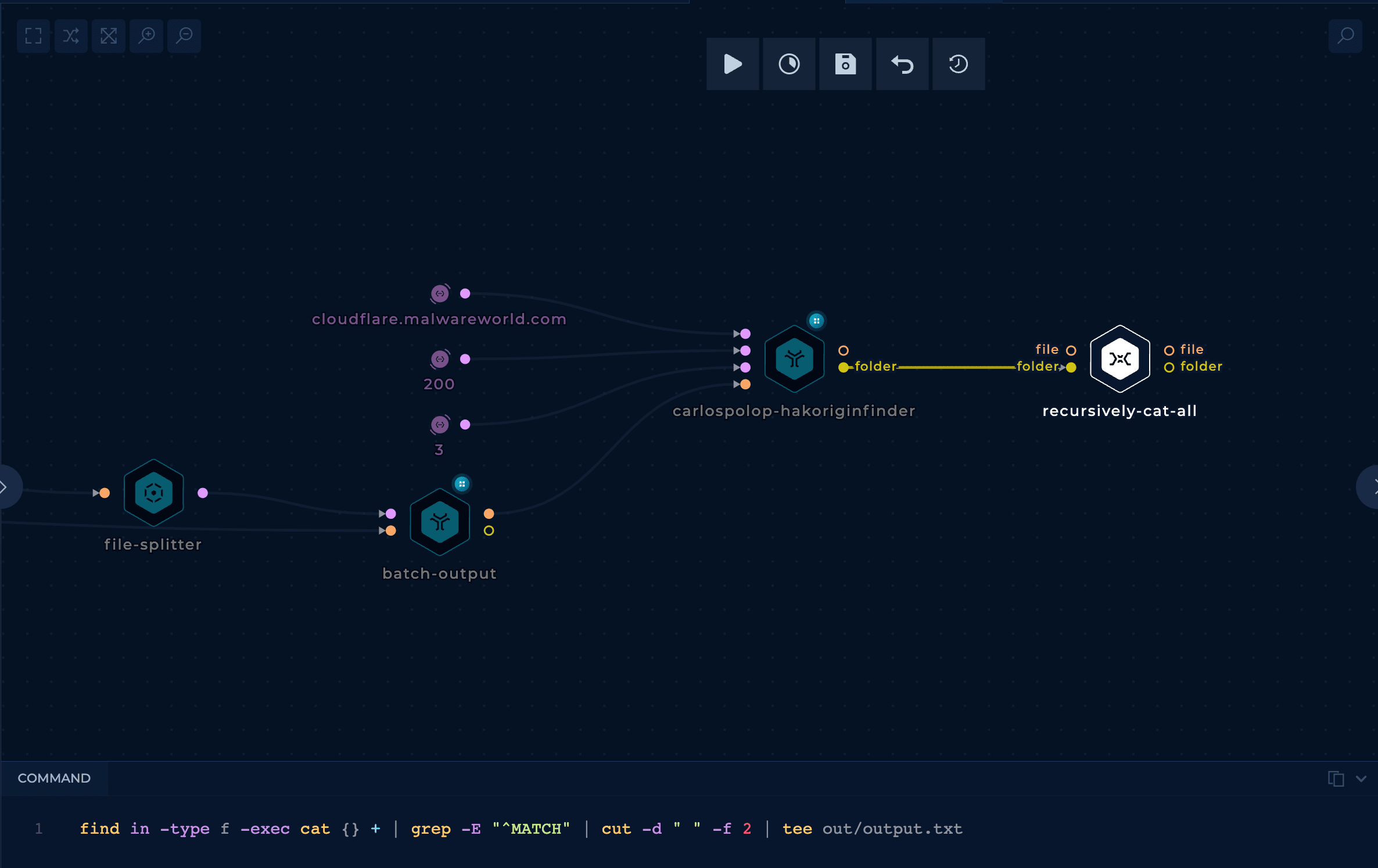
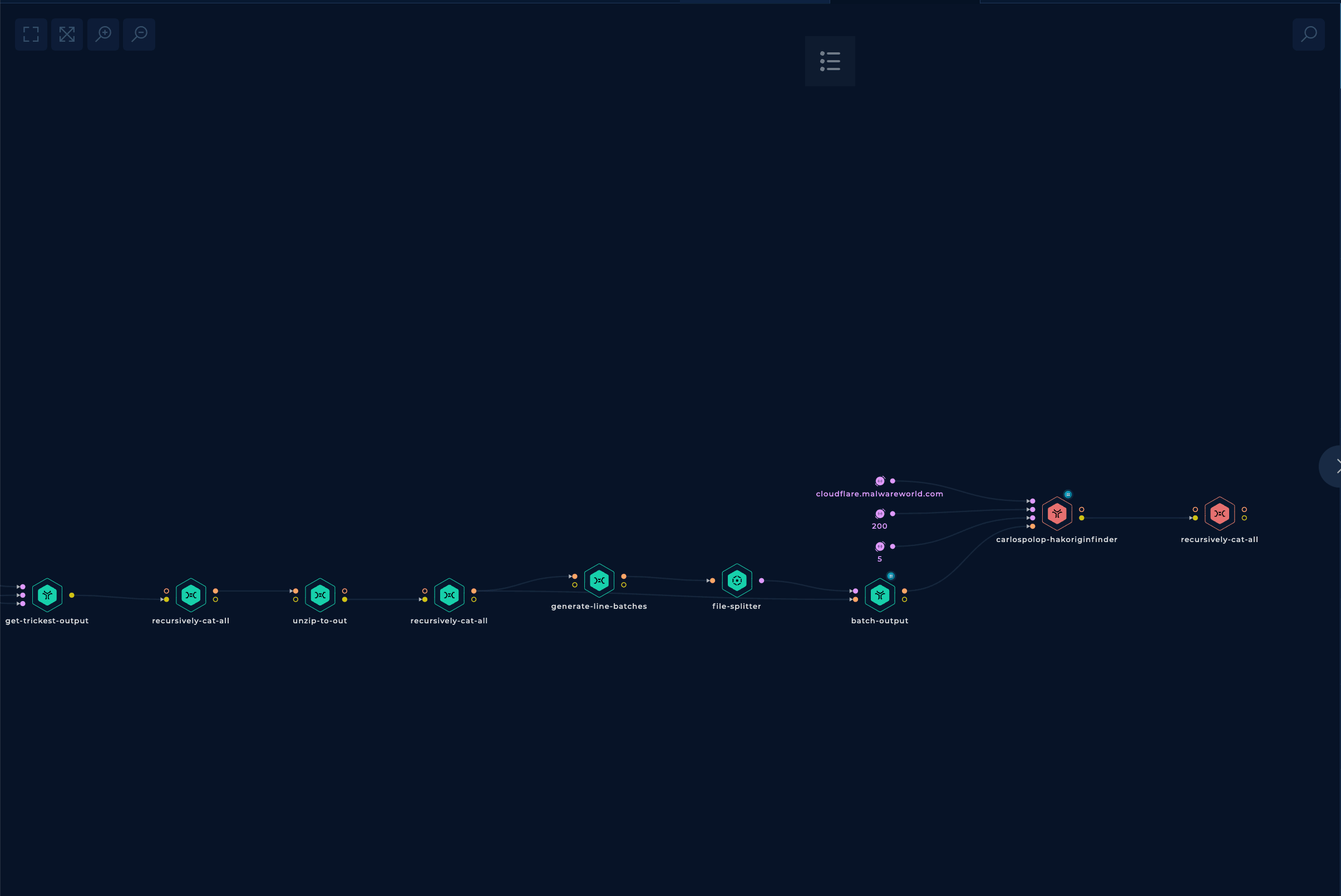
Inside those 13M IPs, there is the one that hosts cloudflare.malwareworld.com. The tool hakoriginfinder is a tool capable of sending http requests to hosts setting the desired Host header, and comparing that response with the original response of the host to find out if it's potentially the same one.
Therefore, a workflow could use this tool over all the previously discovered IP URLs to find the host hosting the web page cloudflare.malwareworld.com.
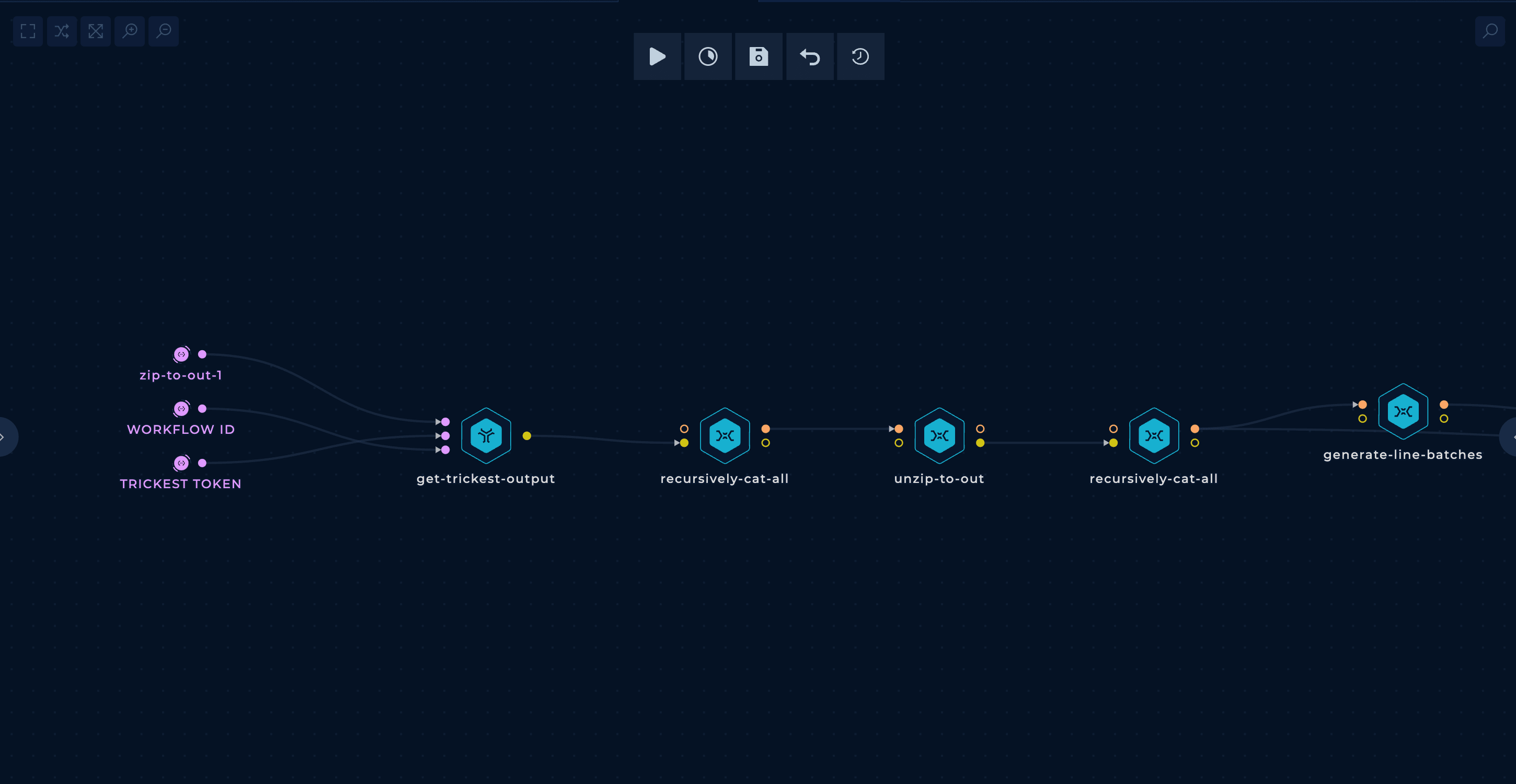
In the initial part of the workflow, the zip from the previous workflow is downloaded and unzipped.
In the second part, the mentioned hakoriginfinder tool is run through all the AWS URLs discovered previously, and a final grep is performed only to get the matches.
Well, this is disappointing... I left it running for 28 hours with 3 medium parallel machines, and it only checked a bit more than 10% of all the URLs.
Then I stopped it, and that's why you see red in the last two nodes.
On a positive note, the origin IP address of the web page appeared in the found matches. So at least it found the origin IP address.
The use of the tool hakoriginfinder was a good idea, as it's capable of recognizing the IP where the page is located, but it was super slow.
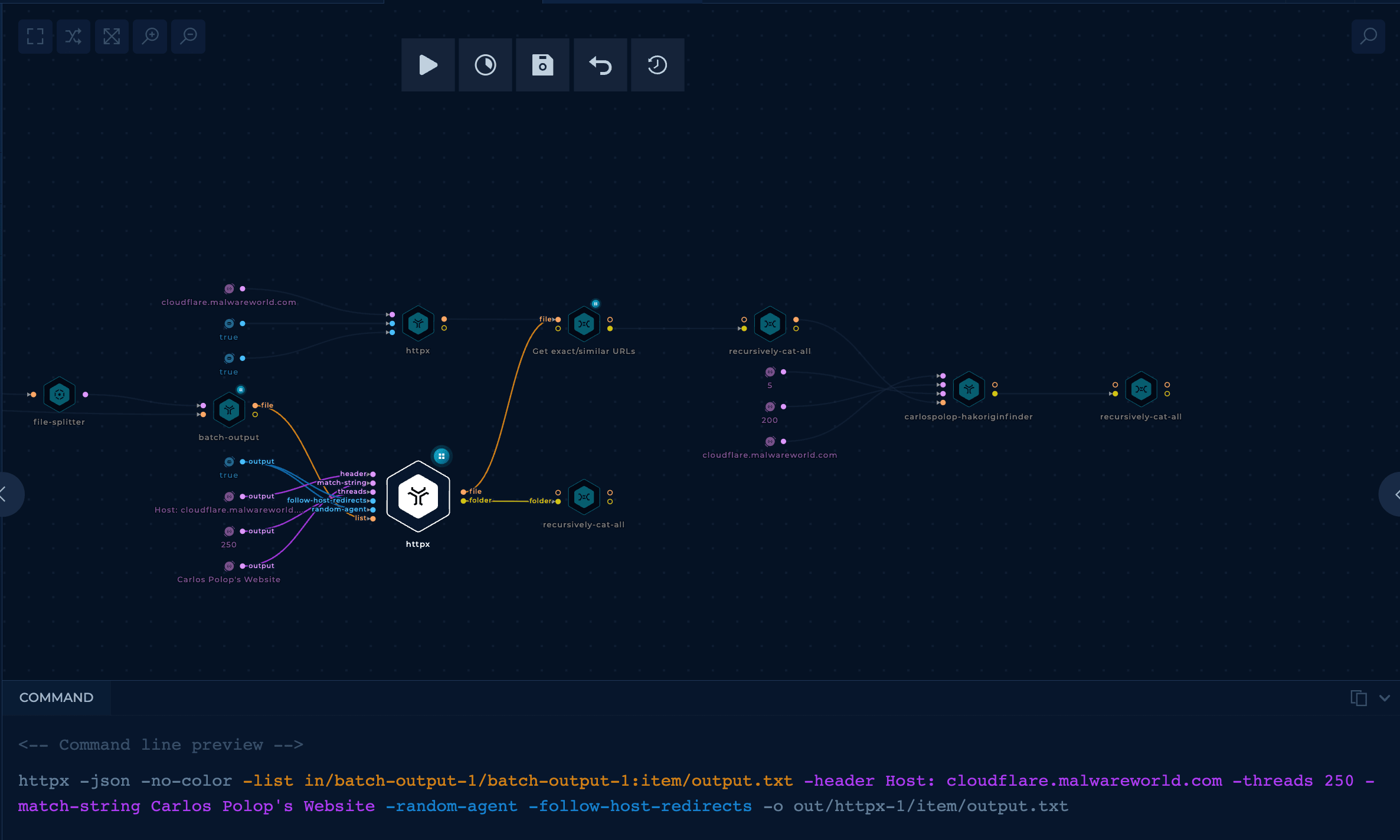
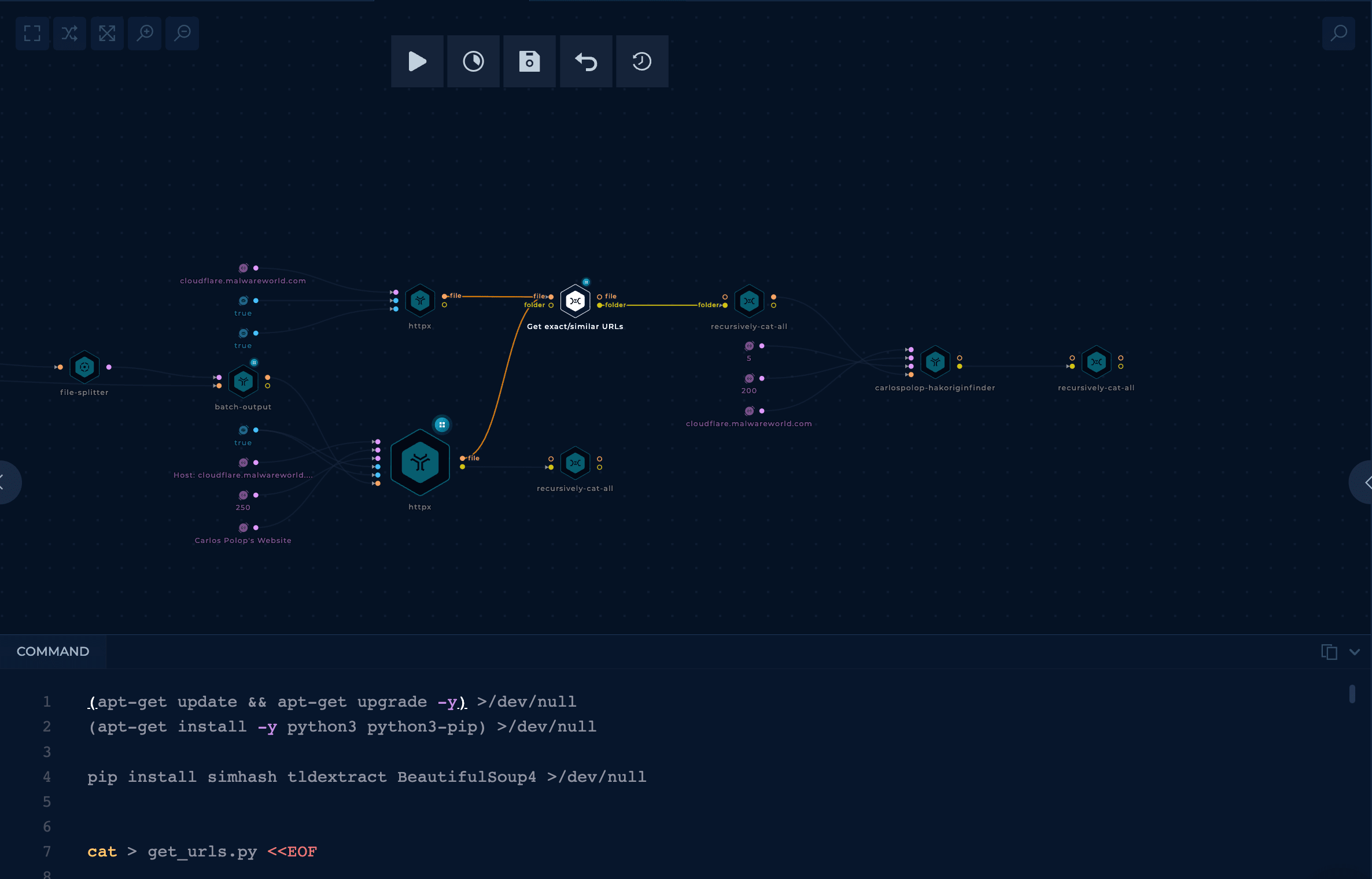
In order to make the IP discovery faster, several changes to the previous workflow were made.
httpx and a unique stringAfter getting the valid URLs from AWS, a httpx node can be used that will access all the URLs sent in the Host header of the searched domain and will filter the results via an expected unique string in the web response.
This will run much faster than hakoriginfinder and will filter a vast amount of URLs from the initial list.
Then, from all those URLs, a custom script can be used to filter even more the list based on the results.
The script performs these actions:
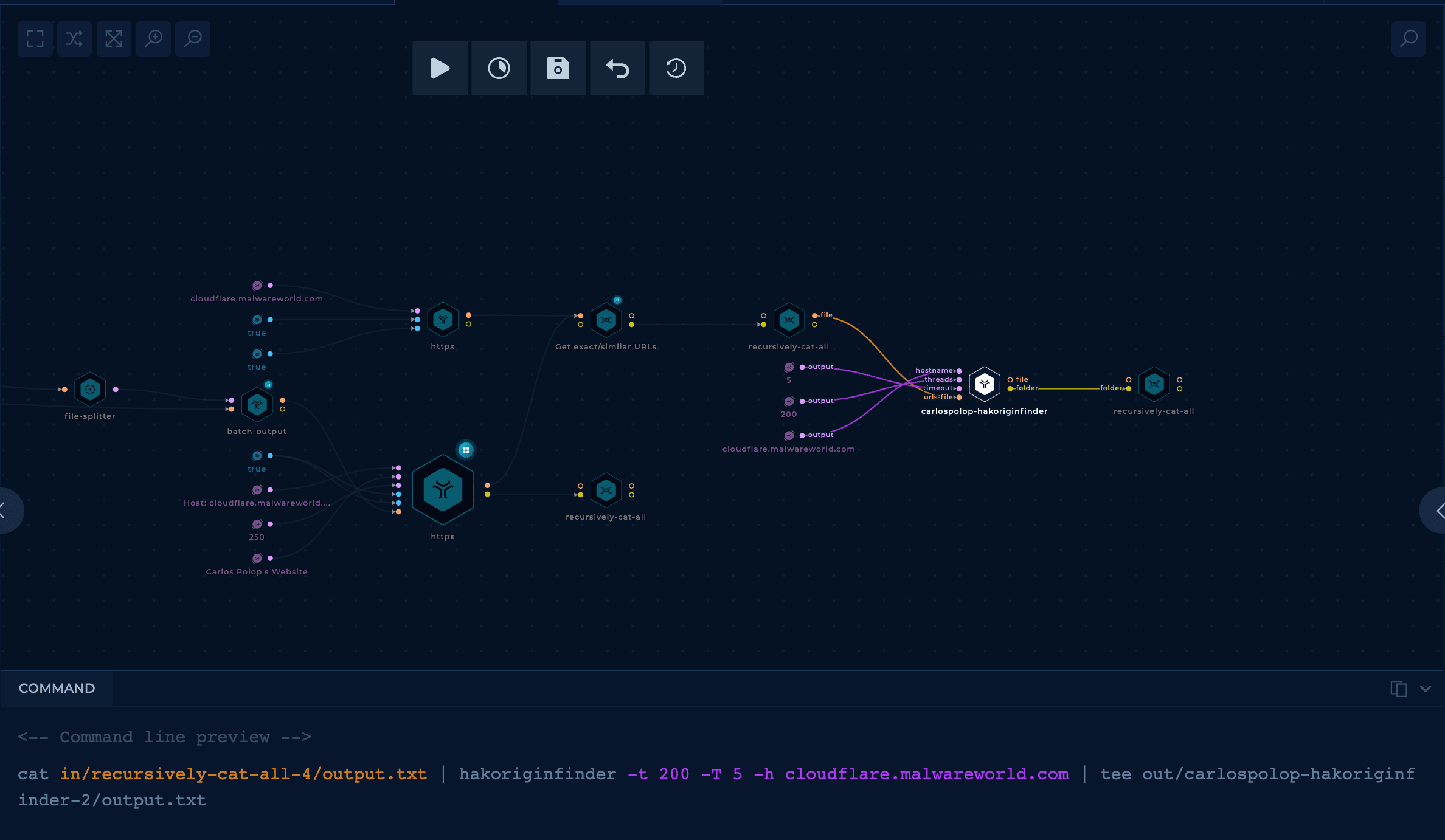
hakoriginfinderAt this point, all of the remaining results have high chance to find the IP. Usually, I add the last filter to find the best results from hakoriginfinder's output.
It took 13h to complete, and the final node had 12 final URLs, the first one we were looking for. Therefore we can say this search was finally a success!
Trickest managed to bypass Cloudflare, find the website IPs behind a proxy, and find the IP. However, let me sum up what you should keep in mind.
If the webpage was correctly configured, it would only allow Cloudflare proxies to access the website's content. Therefore, using this technique, you won't be able to find it (yet companies usually don't protect this).
The final Trickest workflow found 12 final URLs, but only 1 was valid. It's a great result, but probably tuning the custom script would remove the 11 false positives.
13 hours were necessary to complete the workflow with 3 medium parallel machines, but it checked almost 13 million URLs. You can come up with plenty of ideas to improve this workflow and reduce execution time, and the simplest way to reduce it is to use more machines in parallel.
Another improvement that could be performed is to implement some tool/script capable of finding a highly probable unique string from a website so the user doesn't need to indicate it.
Additionally, there are other well-known techniques to discover the origin IP addresses of web pages, like history DNS records. You can find more info about them in HackTricks.
If you enjoyed this blog post and like the idea of automating your work in offensive security, sign up and explore Trickest as a framework.
Get a personalized demo
A 30-minute walkthrough. We map the platform to your stack and answer pricing and deployment questions for your environment.