loading
Loading content
loading
Cloud provider infrastructure mapping scans a provider's entire network and correlates the certificates with your targets. Build the workflow from scratch.

Mohammed Diaa · Head of Workflows
I have been exploring a fascinating recon technique: cloud provider infrastructure mapping. It involves scanning a cloud provider's entire infrastructure and correlating the identified assets with my targets. This approach has helped me find hidden gems like dev/staging environments on unconventional, multiple-levels-deep subdomains that standard subdomain enumeration techniques would have never discovered. But here's the catch: scanning the vast infrastructures of cloud providers can be painfully slow and inefficient. Realizing this challenge, we decided to develop a faster and more efficient workflow that could deliver up-to-date results.
Fast forward, the cloud project was released. We want to provide the community with an always up-to-date and freely accessible cloud map of all major cloud service providers. It currently contains the SSL/TLS certificate data of AWS's infrastructure, with plans to expand it with more providers and more data.
In this blog post, we'll explore the reasons behind the creation of this workflow, its development process and the design choices that shaped it, practical applications for using its results in your recon and attack surface discovery processes, and some ideas on how you can take it to the next level by making your own updates and modifications.
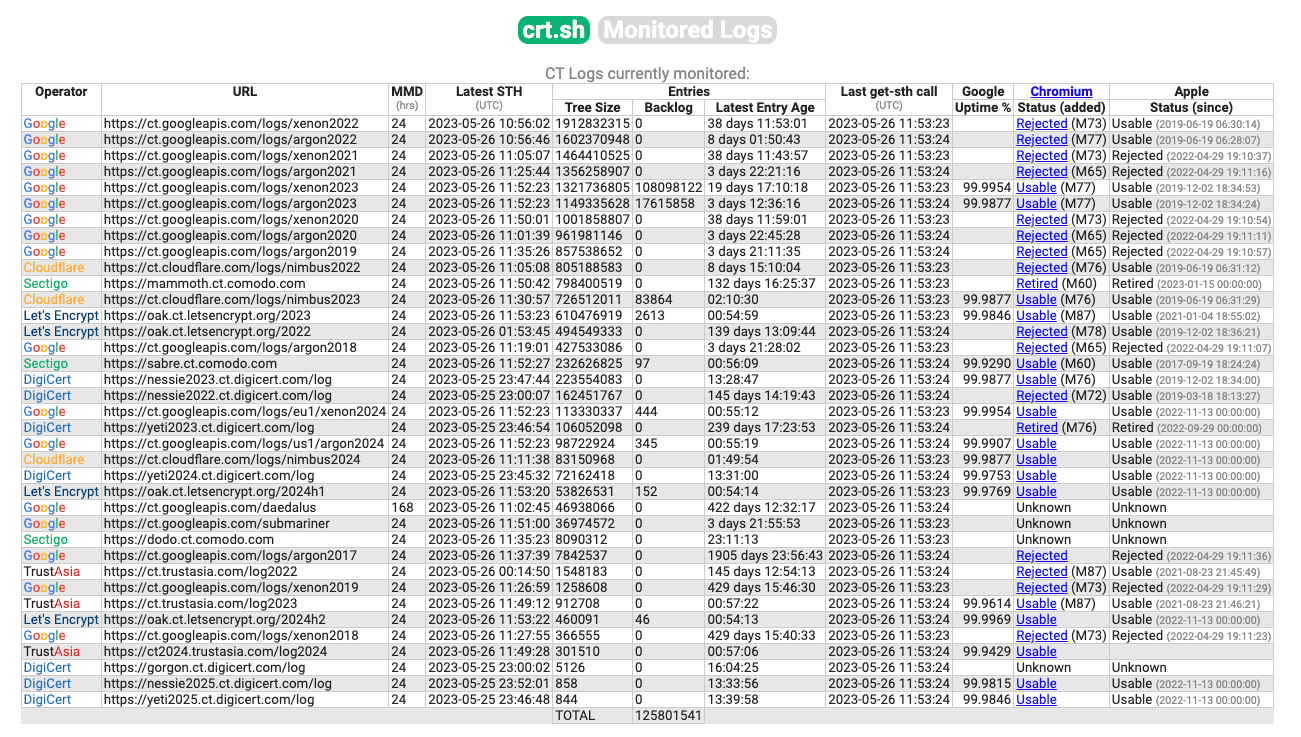
While certificate transparency logs, such as crt.sh should have the same data in theory, they do come with a few limitations.
To understand this better, we need some context on how Certificate Transparency works and how platforms like crt.sh play into the mix.
When a Certificate Authority issues a new certificate, it submits it to certain public services responsible for tracking issued certificates known as CT Logs. These logs make a commitment to include the certificate in their public records within a specified timeframe, known as the Maximum Merge Delay (usually around 24 hours). CT Monitors, such as crt.sh, query these logs and update their databases accordingly. You can find the list of CT logs monitored by crt.sh and learn more about Certificate Transparency.
Delays occur primarily during the process of accessing the logs and indexing their content into the CT Monitor's database. If you check crt.sh's monitored logs, you'll notice a Backlog column, indicating the number of certificates issued and included in the CT Log but not yet indexed by the CT Monitor. The backlog is calculated by subtracting the log tree size from the index of the last entry. While crt.sh does an amazing job of keeping up, it is not real-time. Particularly, when dealing with popular logs that receive constant updates like those of Google and Cloudflare, the backlog can grow substantially, leading to delays of several days.
Certificate Transparency's purpose is to bring transparency and verifiability to publicly trusted certificates. So by definition, self-signed certificates and certificates issued by Private Certificate Authorities don't make it into CT Logs, which means they don't find their way into the databases of CT Monitors. The workflow we will explore shortly managed to enumerate around 7 million certificates. Among those, approximately 450,000 turned out to be self-signed. These self-signed certificates featured about 65,000 unique hosts in the Common Name field. Let's crunch the numbers.
So, self-signed certificates accounted for roughly 6.5% of the total certificates, with around 1% more unique CNs thrown into the mix. Now, I know the percentage might not seem astronomical, but from my experience, hosts with self-signed certificates tend to hold some hidden gems. Think along the lines of dev or staging environments, which makes this 1% a lot more meaningful.
Along the way, I encountered a few other challenges, such as the need for more complex queries and some occasional downtime. However, these issues can be addressed by directly accessing the PostgreSQL database instead of relying on the web UI.
psql -h crt.sh -p 5432 -U guest certwatchSo those reasons (and because we've built this new incredible workflow engine that has taken the scalability and performance of Trickest workflows to new heights), I decided to collect my own data. It was the perfect opportunity to make my process more efficient, create a valuable resource for the community, and put our new solution to the test.
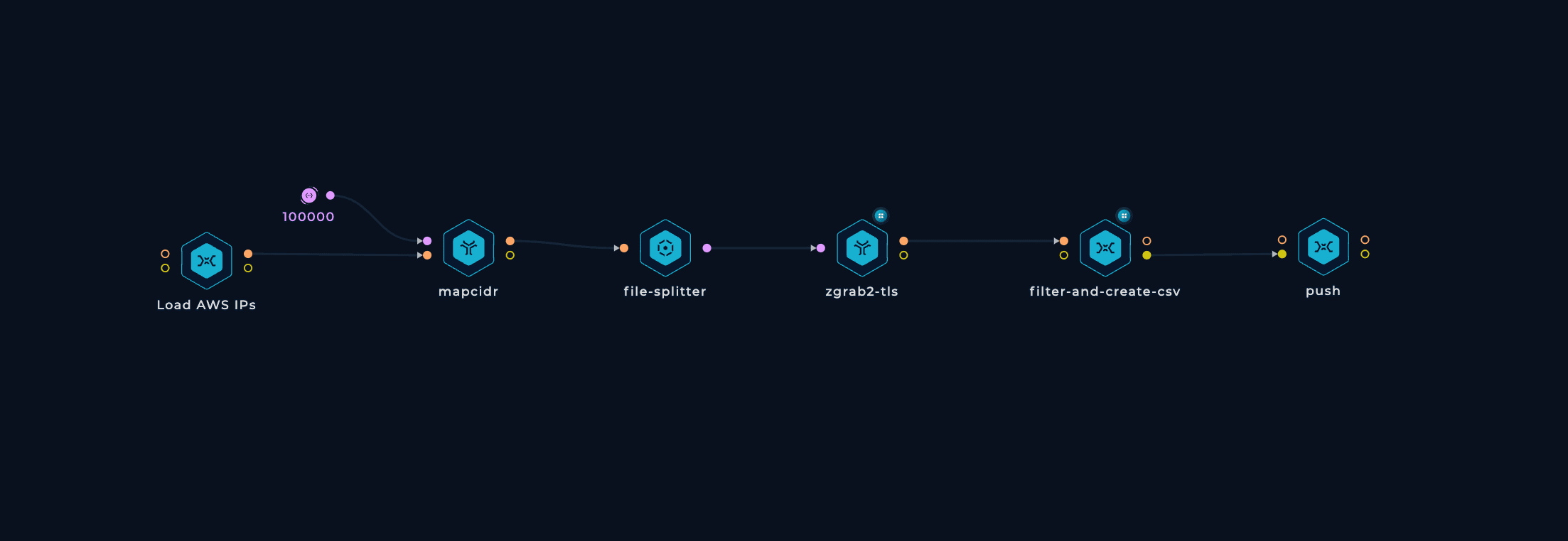
Now, let's explore how the workflow was built, step by step, and the optimizations we made along the way.
To begin, we used a convenient JSON file published and updated by Amazon that contains the complete list of AWS IP ranges.
{
...
"prefixes": [
{
"ip_prefix": "3.2.34.0/26",
"region": "af-south-1",
"service": "AMAZON",
"network_border_group": "af-south-1"
},
...
]
}Within this file, you'll find a list of objects under the prefixes key. Each object includes an ip_prefix field indicating the IP range.
We wrote a simple shell script to download the file and extract the IP ranges:
curl -s https://ip-ranges.amazonaws.com/ip-ranges.json | jq -r '.prefixes[].ip_prefix' | tee out/output.txtAfter running this script, we obtained a total of 7,379 ranges, that contain a staggering 135.5 million IP addresses.
jq -r '.prefixes[].ip_prefix' ip-ranges.json | mapcidr -c
135527859However, not all of these ranges are relevant to our project, presenting an opportunity for optimization.
Each range is associated with a service field, indicating the AWS service it is used for. While this field's values include well-known AWS services like EC2, CloudFront, S3, etc, there is also a special service called AMAZON that duplicates the IP ranges of all other services.
{
...
"prefixes": [
{
"ip_prefix": "3.2.34.0/26",
"region": "af-south-1",
"service": "AMAZON",
"network_border_group": "af-south-1"
},
...
{
"ip_prefix": "3.2.34.0/26",
"region": "af-south-1",
"service": "EC2",
"network_border_group": "af-south-1"
},
...
}The AWS documentation confirms this:
Specify
AMAZONto get all IP address ranges (meaning that every subset is also in theAMAZONsubset).
Considering this, rescanning the ranges of the AMAZON service is redundant. We can modify the JQ query to exclude these ranges:
.prefixes[] | select(.service!="AMAZON") | .ip_prefixAfter filtering, the number of IP addresses decreased to less than half:
jq -r '.prefixes[] | select(.service!="AMAZON") | .ip_prefix' ip-ranges.json | mapcidr -c
62854678But again, do we really need to scan all of these IP addresses?
Further research revealed that only the EC2 and CloudFront services support custom SSL certificates. The hosts of other services, when they have a certificate, they are certificates issued by AWS and have subdomains like amazonaws.com or *.aws in the Common Name and Alternative Name fields, and no Organization or Organizational Unit fields. As a result, these services are irrelevant to our research as they don't contain any owner-specific data.
And we can update the JQ query accordingly
.prefixes[] | select(.service=="EC2" or .service=="CLOUDFRONT") | .ip_prefixAfter this step, the final count becomes:
jq -r '.prefixes[] | select(.service=="EC2" or .service=="CLOUDFRONT") | .ip_prefix' ip-ranges.json | mapcidr -c
61458617As it turns out, we only need to scan 45% of the initial IP ranges, which is a big improvement. However, there are still 61.4 million IP addresses to handle. Another round of optimization is needed.
The core of this workflow is going to be a client that can retrieve SSL certificates from the IP addresses within the target IP ranges. The ideal tool should:
After experimenting with various tools, we found that good old zgrab2 emerged as the clear winner. It checked all the boxes: delivering accurate results at a speed of approximately 120 results per second (with a significant portion hitting the timeout), and it could smoothly run 1000 concurrent processes, making almost full use of the resources of a Trickest small machine.
We currently use the tls module, which does only the TLS handshake without performing an unnecessary HTTP request. In the future, if we need to collect more HTTP-specific data, we'll switch to the http module.
We also gave integrating an L4 port scanner a shot to quickly weed out non-existent hosts before running zgrab2. It did speed up the workflow, but accuracy took a hit with a bunch of false negatives. We're digging deeper into this to figure out why exactly. Maybe some machines got blocked or "shunned" after the first connection, messing up the TLS certificate grab. Or maybe the ratio of false negatives in most port scanners was just too high at that scale. It could be a combination of these factors or something else entirely. Anyhow, the performance boost wasn't worth sacrificing accuracy, so for now, we're sticking with zgrab2 as is.
With IP range filtering and tool selection taken care of, we now reach the final piece of the puzzle: scaling out the workflow.
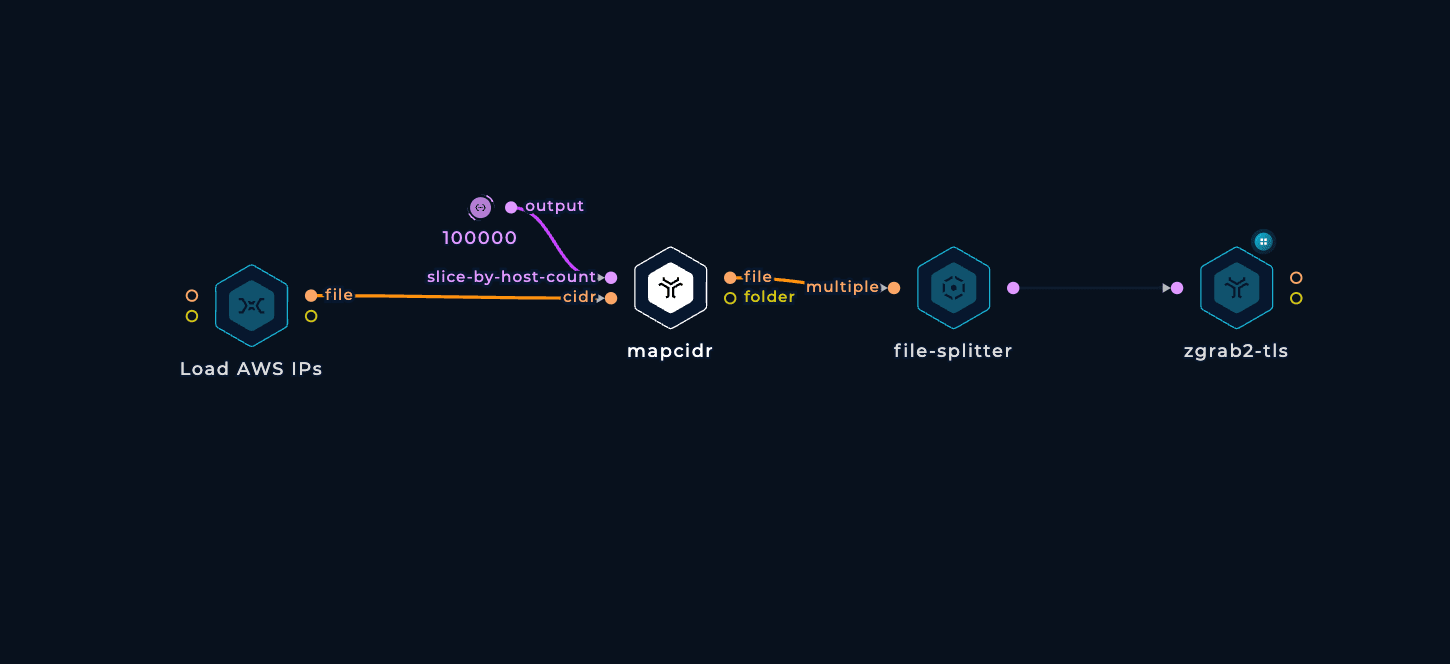
To be able to run this workflow regularly and have up-to-date results, horizontal scaling is necessary. We need to spin up tens of parallel machines with zgrab2 installed and updated, split up the initial IP ranges list into lines, pass each line to a machine, run zgrab2, keep doing this until all ranges are processed, and then collect the outputs. Luckily, we have a dedicated node that handles all of these tasks.
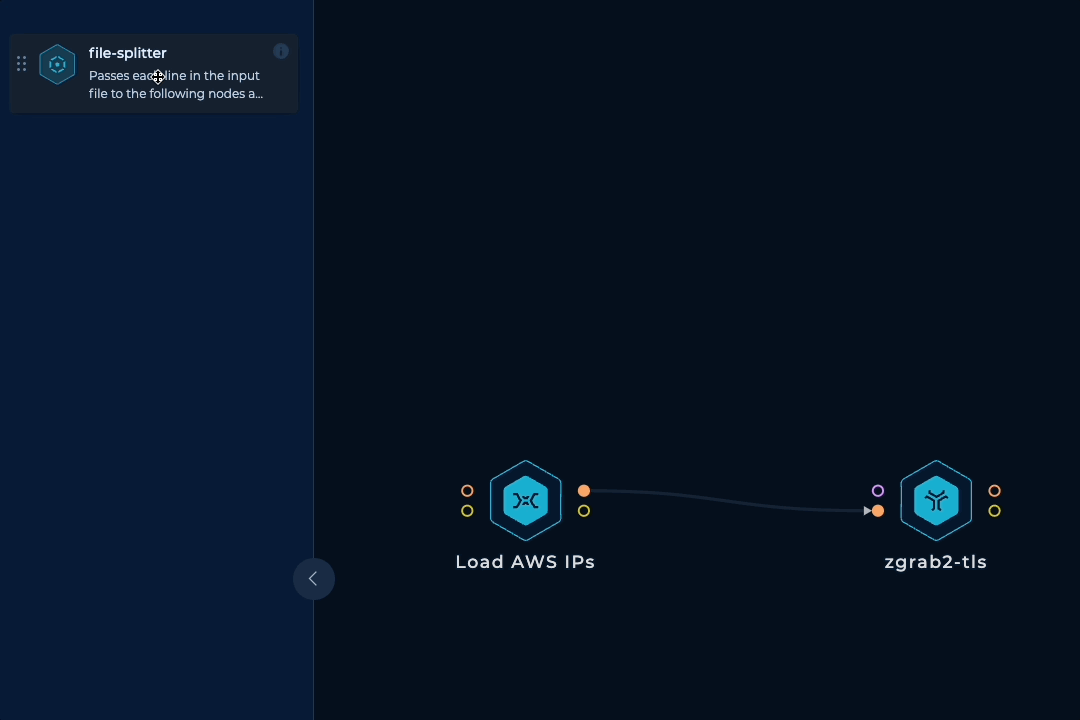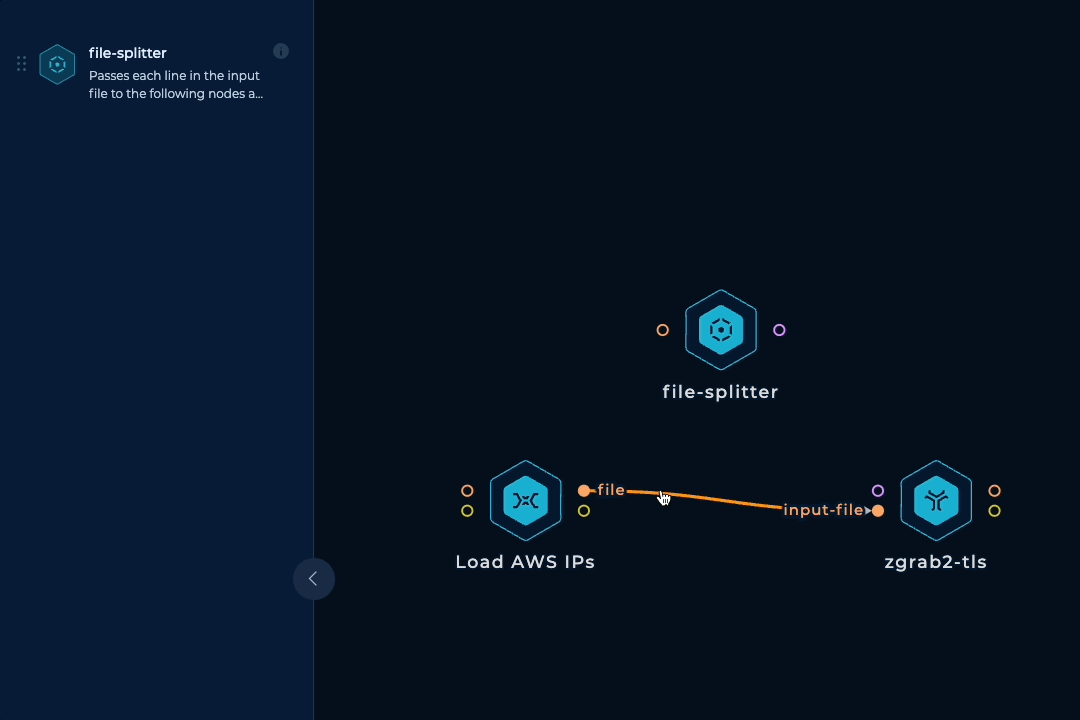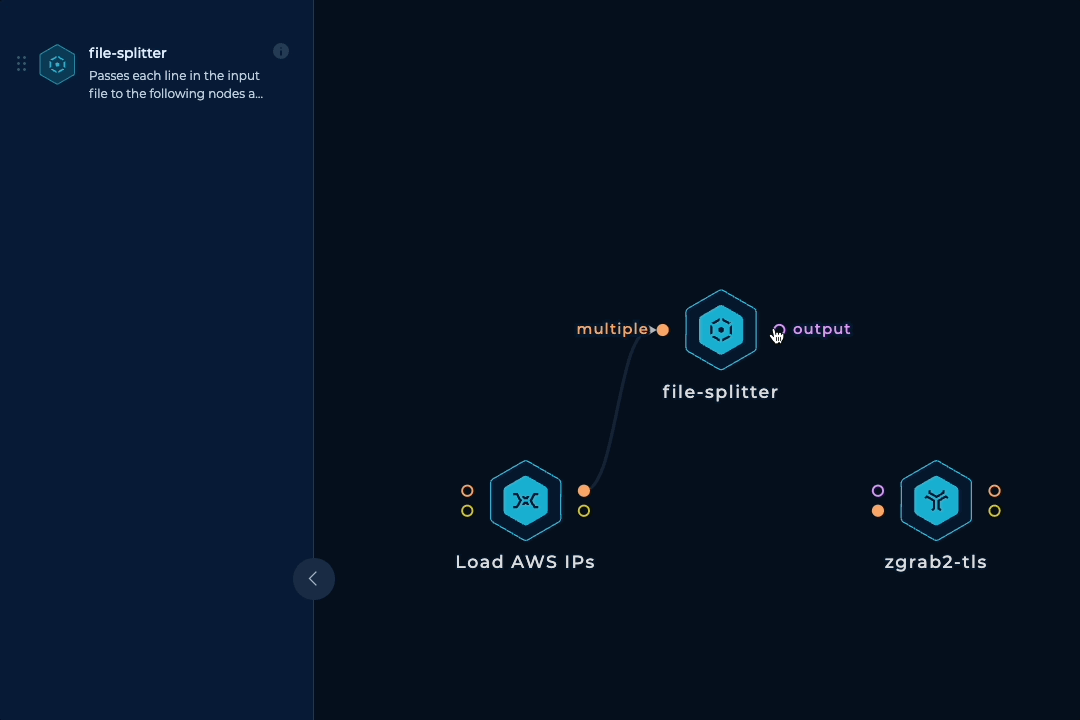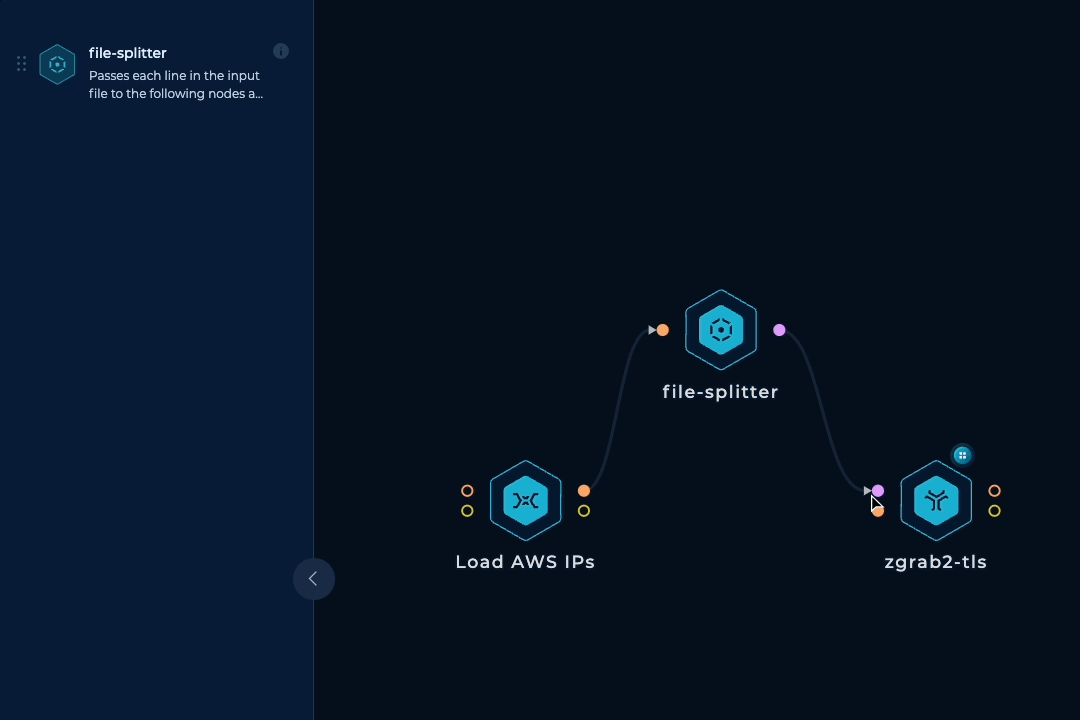
To make things more reliable and balanced, we can take an extra step to prevent any IP range from getting too large and overwhelming a single machine. If an IP range has more than 10000 IP addresses, we can simply split it into smaller ranges. This can be done easily with mapcidr and its slice-by-host-count input.
Since zgrab2 writes its output in a super detailed JSON format, we can use a shell script to extract the relevant fields and save them in a CSV file. This JQ query filters out results that don't have a certificate field (indicating non-responsive or timed-out hosts), extracts the relevant fields if available, and converts them to CSV format with | as the internal column value delimiter.
Finally, we have a small script that receives the CSV files, splits them into smaller chunks of 0.5 MB (to make sure GitHub renders them properly), adds the CSV header with column names, and pushes them to the trickest/cloud GitHub repository. And that's it! The workflow is complete.
And this is the beautiful result generated by the workflow:
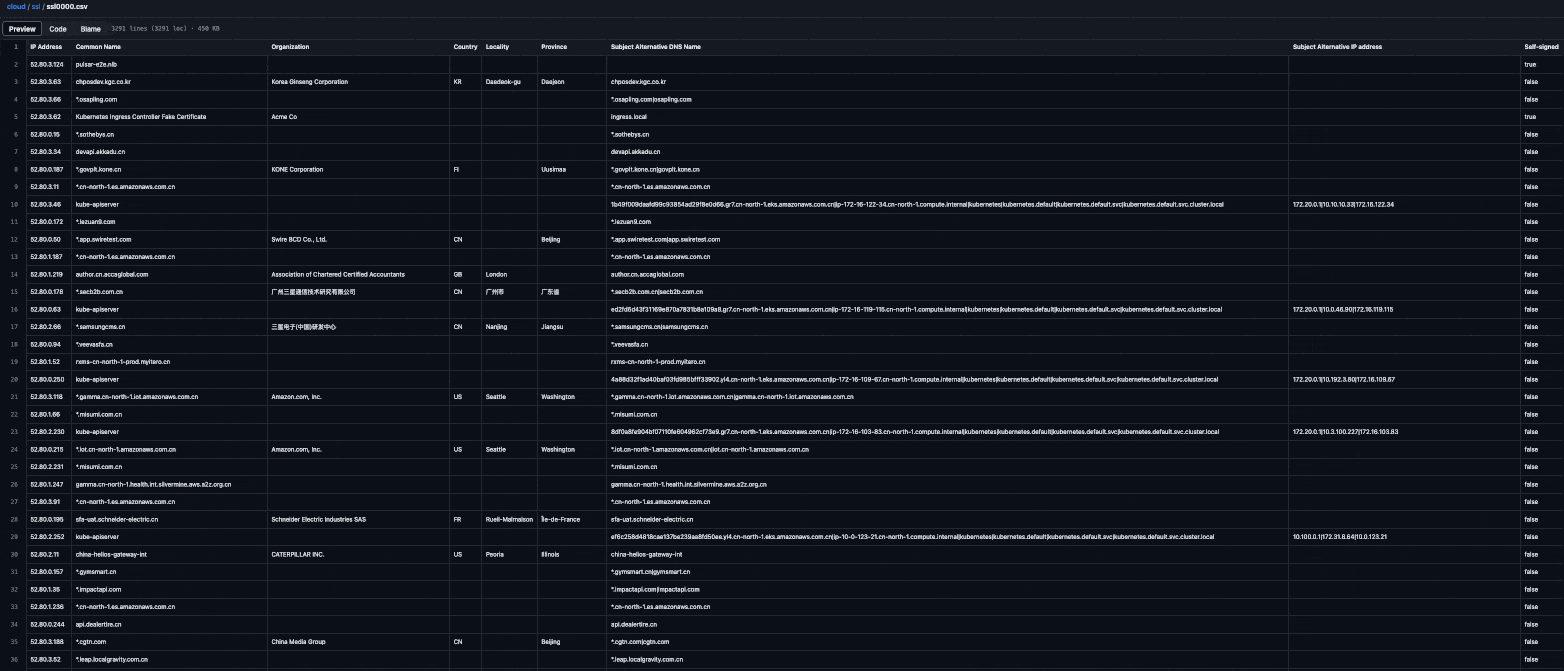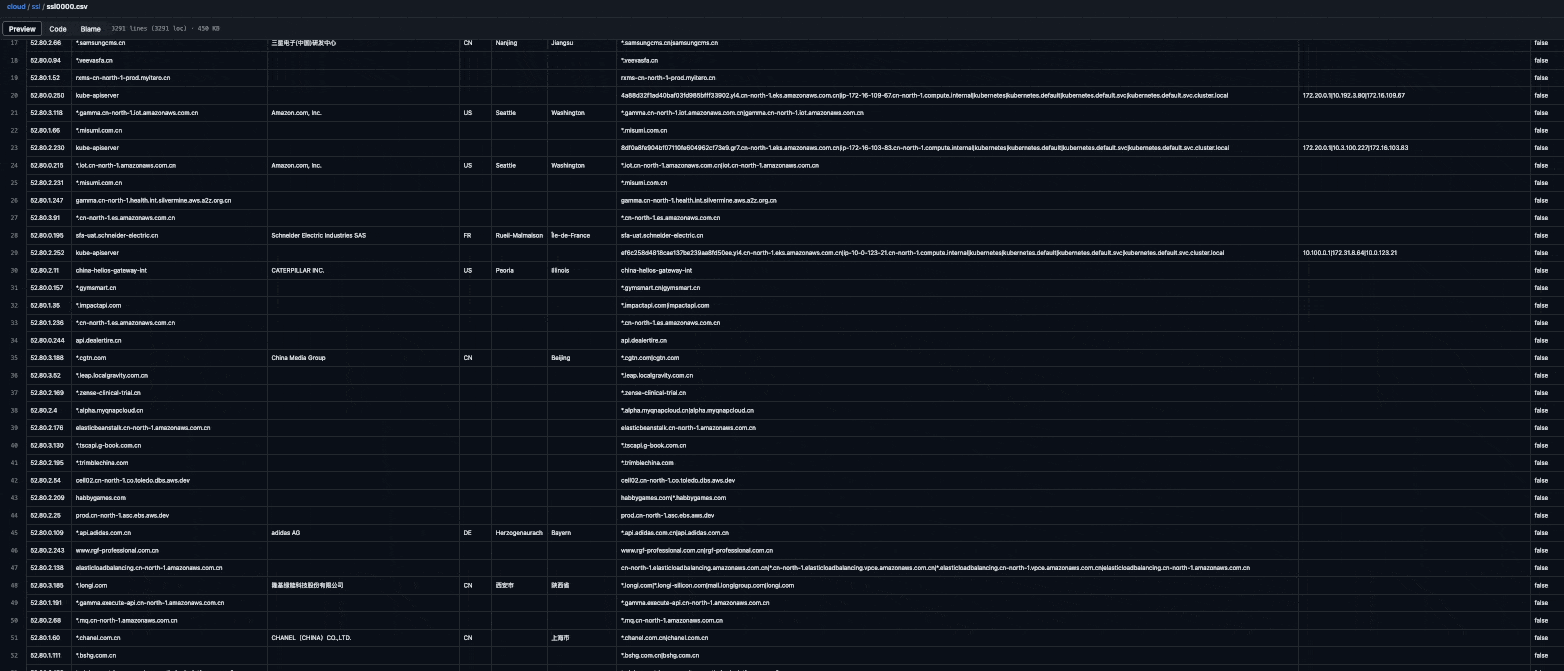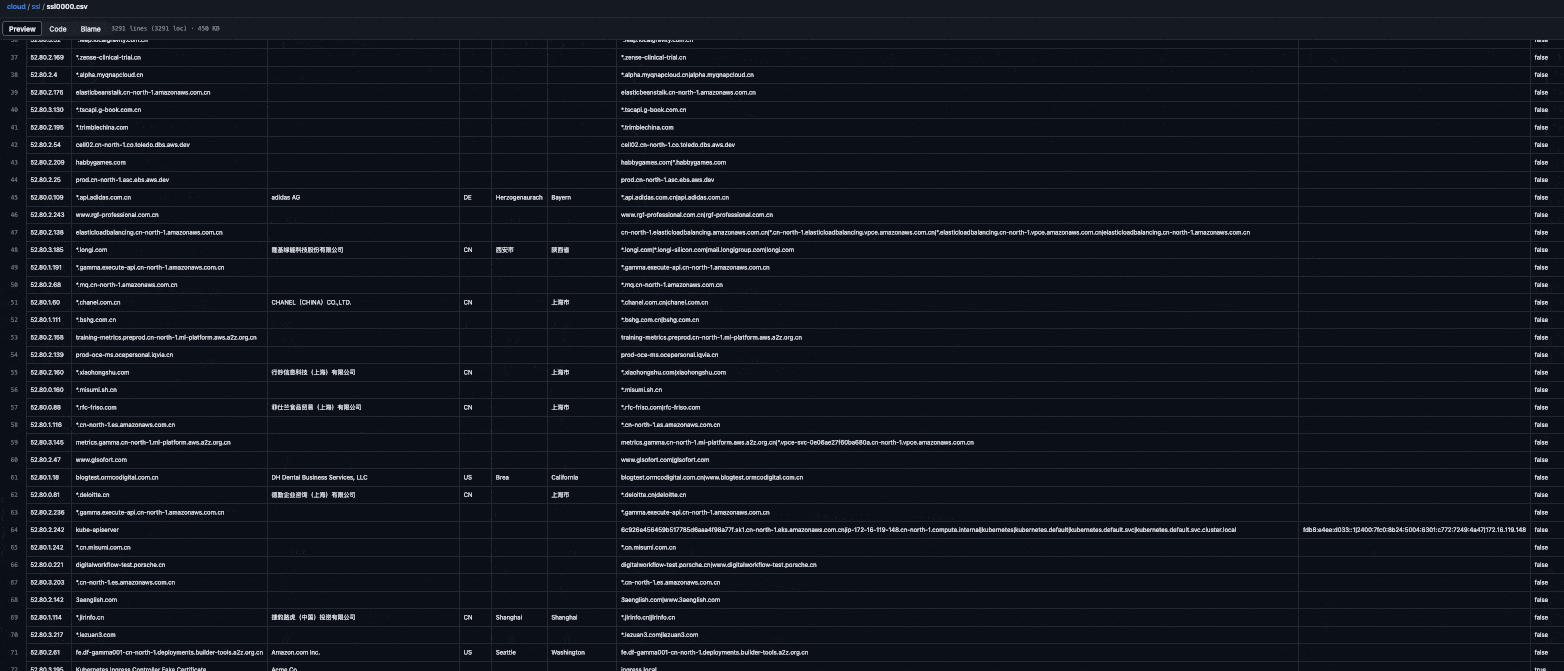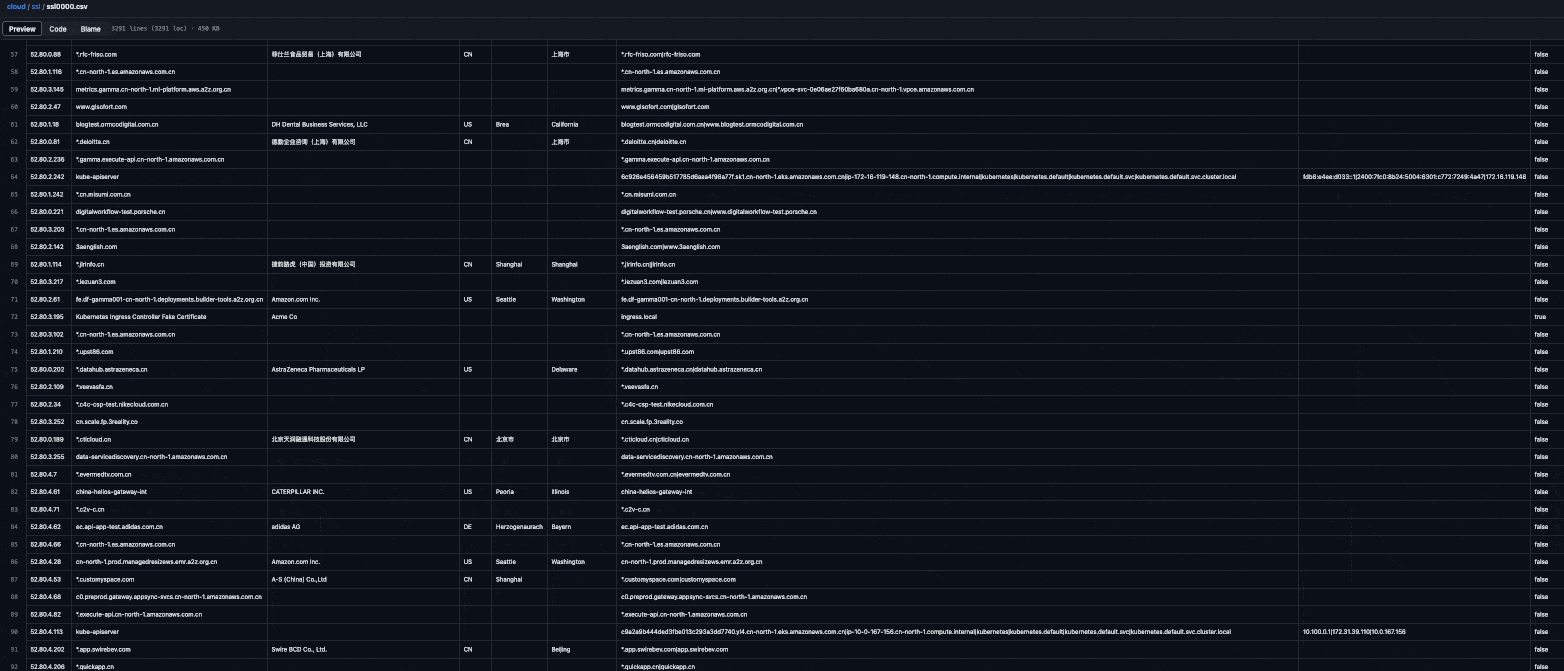
Enumerate subdomains of your target domains: Search for your target's domain names (e.g., example.com) and find matches in the Common Name and Subject Alternative Name fields.
Enumerate root domains and subdomains of your target companies: Search for your target's company name (e.g., Example, Inc.), find matches in the Organization field, and explore the associated Common Name and Subject Alternative Name fields. The results will probably include subdomains of the domains you're familiar with and if you're in luck you might find new root domains and expand the scope.
Enumerate possible sub-subdomain enumeration target: If a certificate is issued for a wildcard domain (e.g., *.foo.example.com), there's a good chance you can find additional subdomains through brute-forcing. And you know how effective this technique can be. Here are some wordlists to help you with that!
Perform IP lookups: Search for an IP address (e.g., 3.122.37.147), find matches in the IP Address and Subject Alternative IP Address fields, and explore the Common Name, Subject Alternative Name, and Organization fields.
Discover origin IP addresses to bypass proxy services: When a website is hidden behind security proxy services like Cloudflare, Akamai, Incapsula, and others, you can search for the hostname (e.g., example.com). This search may uncover the origin IP address, allowing you to bypass the proxy. We’ve previously shared a similar technique about bypassing Cloudflare.
Get a fresh dataset of live web servers: Every IP address in the dataset represents an HTTPS server running on port 443. You can use this data for large-scale research without wasting time collecting it yourself.
This workflow is available in the Trickest Workflows Library for registered users. You can start using it right away to create your own cloud (or internet-wide) asset dataset. If you're not yet a Trickest user, sign up to view it.
With all the basic functionality already set up, you can dive straight into the data or even adapt the workflow and make your own edits depending on what you want to achieve. Here are some ideas.
The IP ranges are loaded with a simple shell script and are isolated to one self-contained node, so you can easily edit it to maybe load GCP's IP ranges instead of AWS?
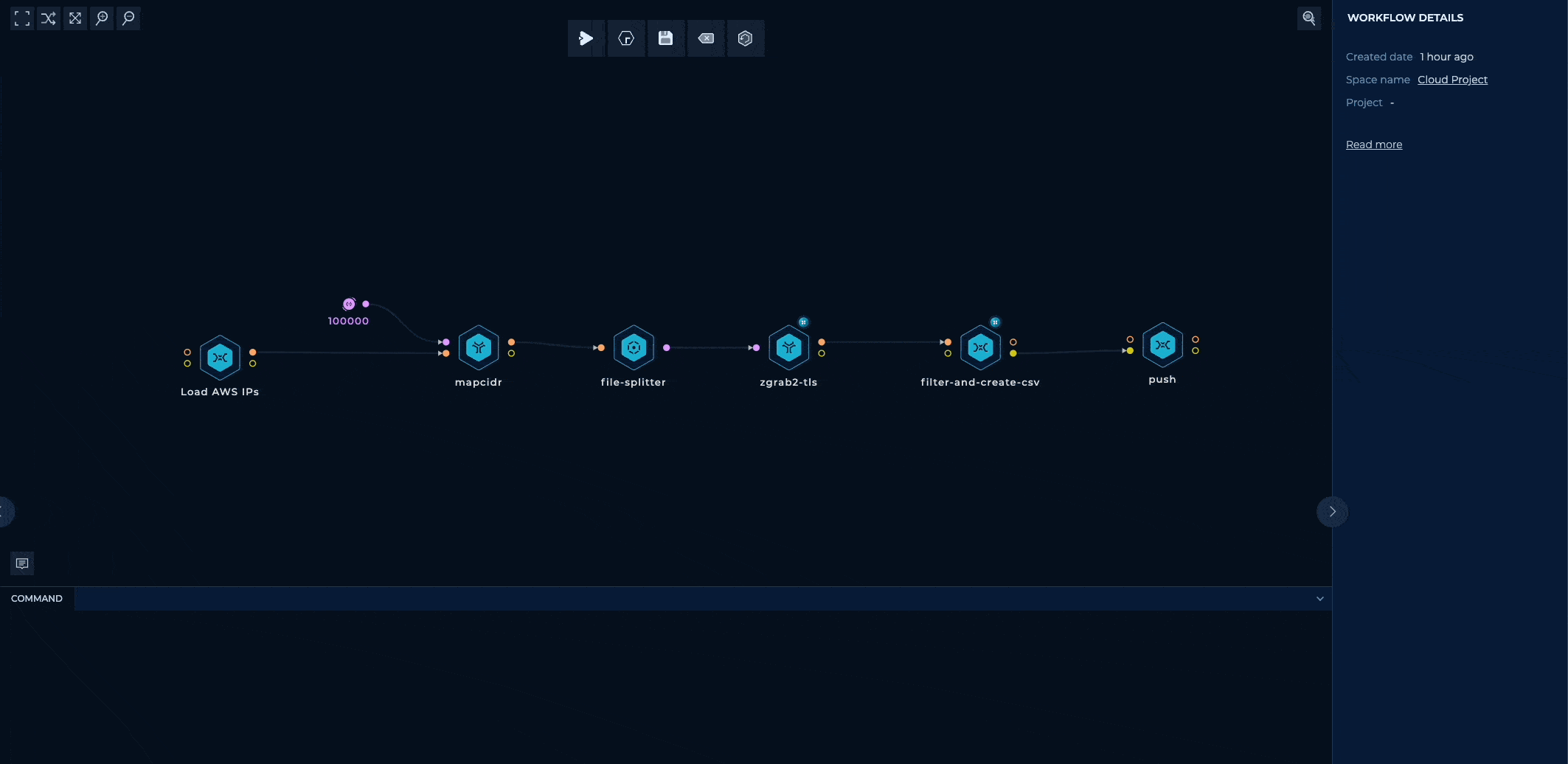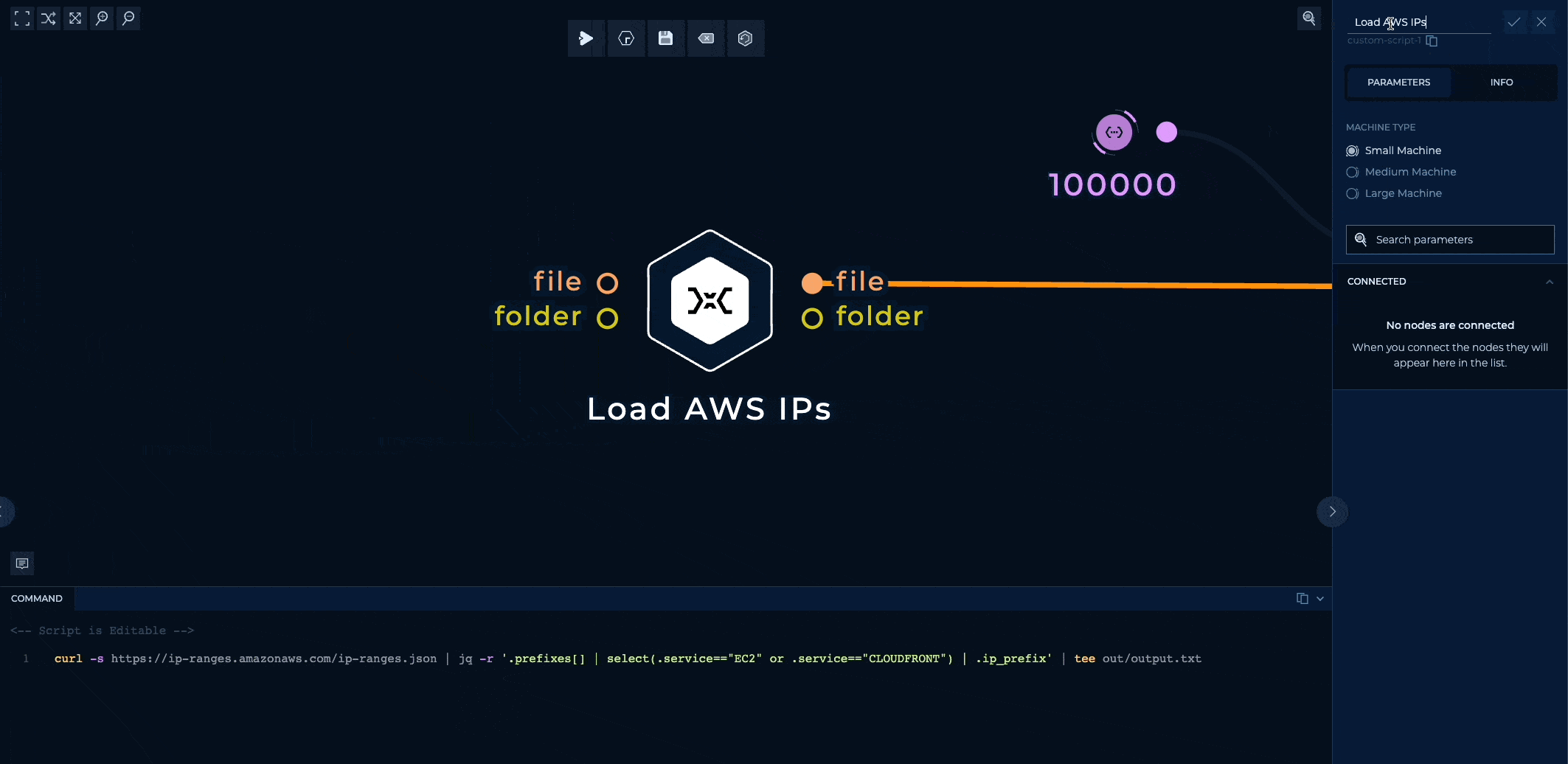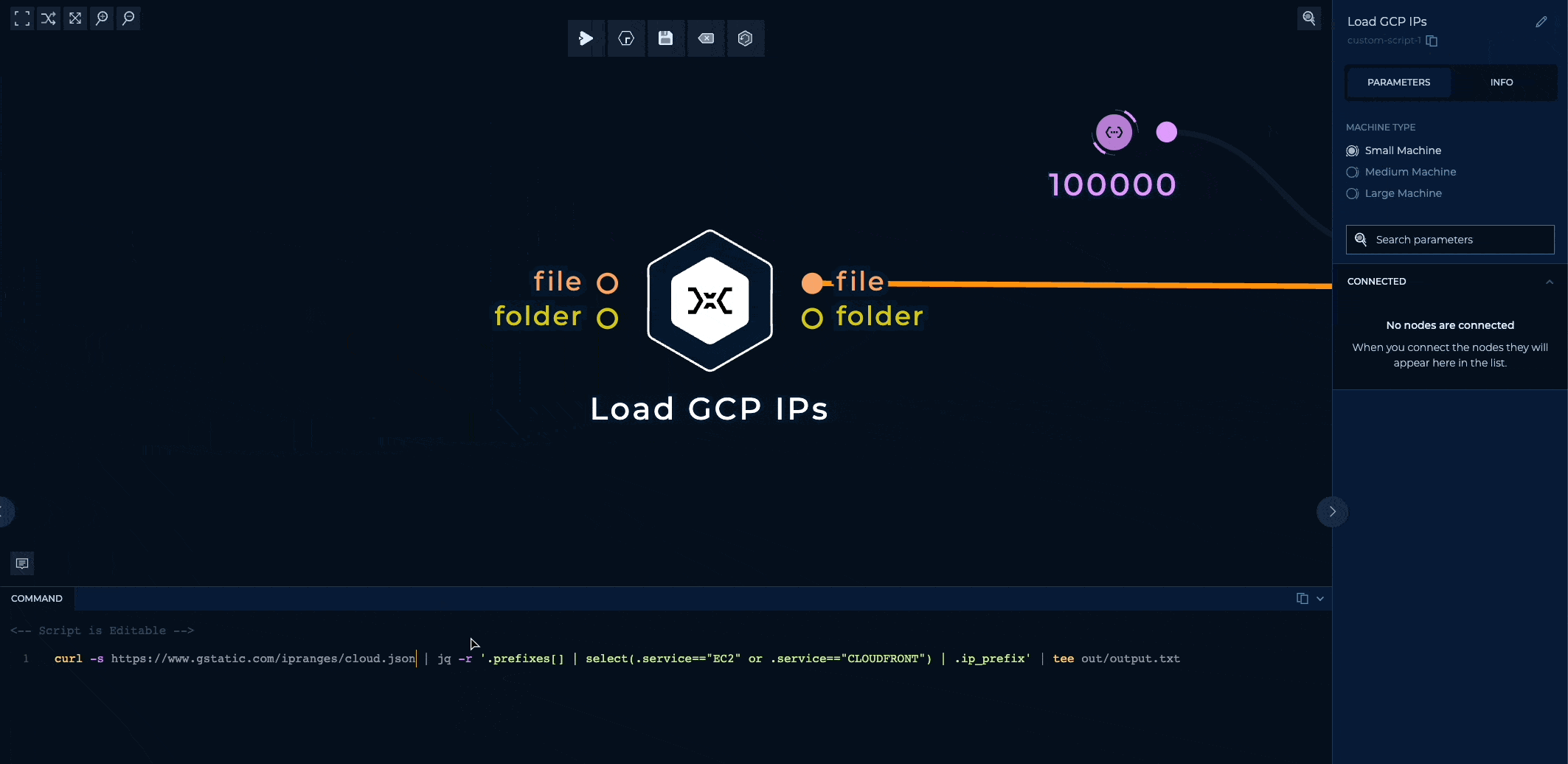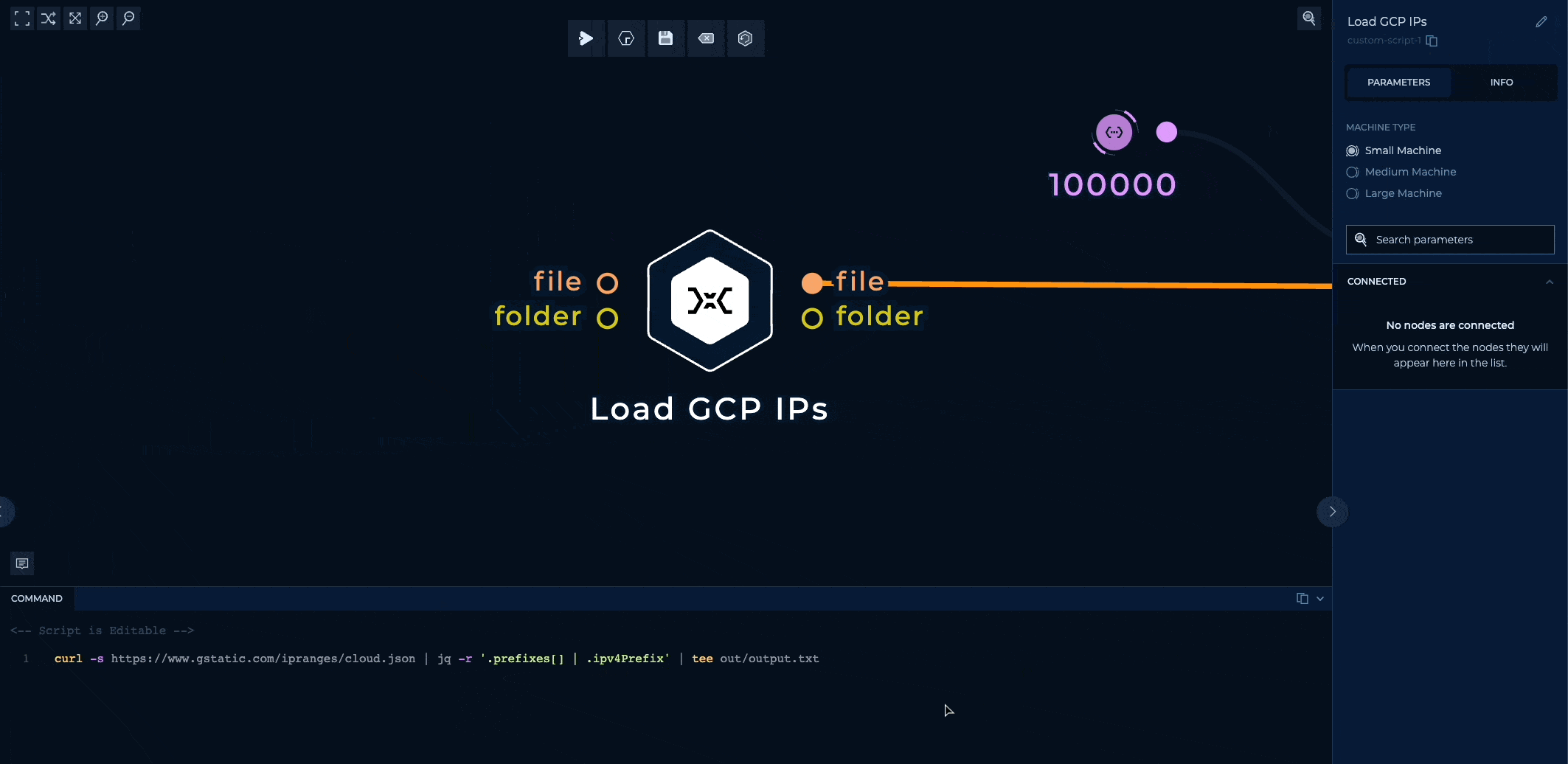
Or your own IP ranges?

Or even the entire internet (New project?)
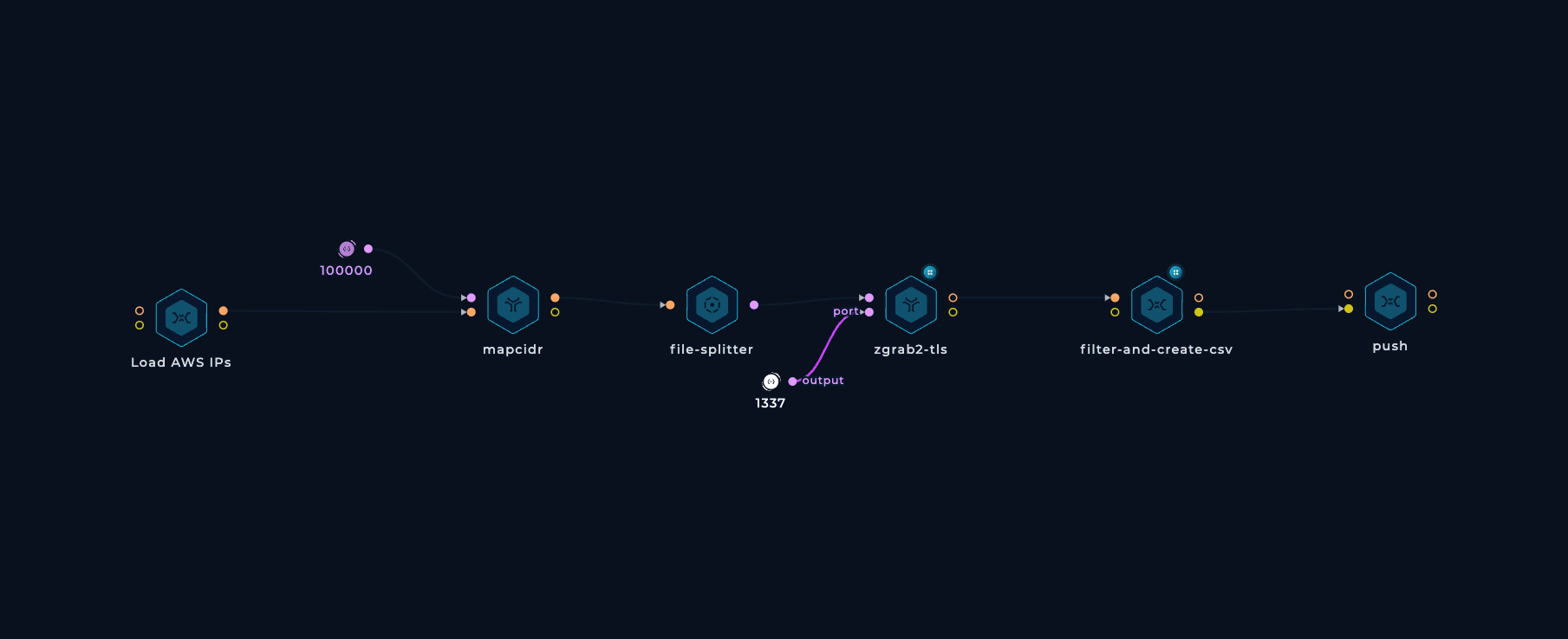
By default, zgrab2-tls scans port 443. You can use any other port you want though.
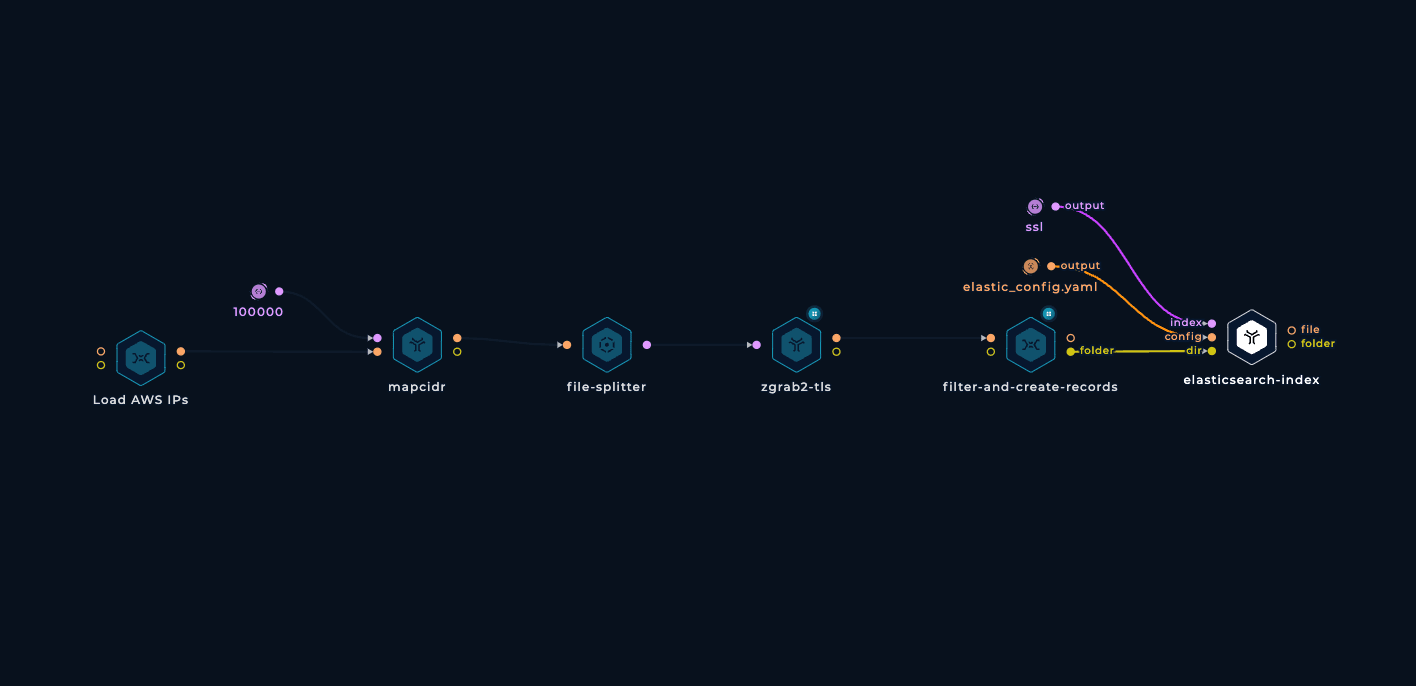
CSV files are totally fine for basic usage but if you need more complex queries, importing the data into a proper database like Elasticsearch might be a good idea.
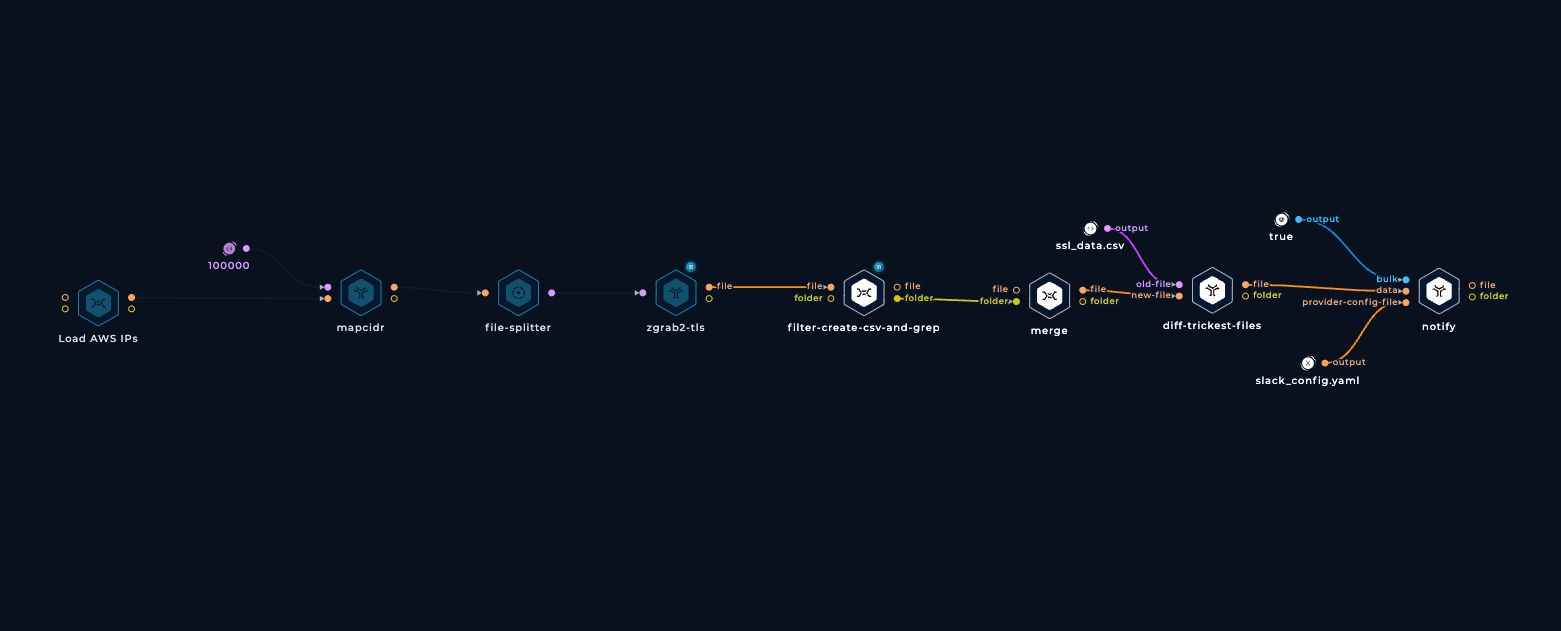
You can add a script to the workflow to search for assets related to your company and get notified about them. This is doable by simply grepping for your company name, diffing against the results of the last execution of the workflow, and sending the diff results to yourself on Slack, Telegram, Teams, etc.
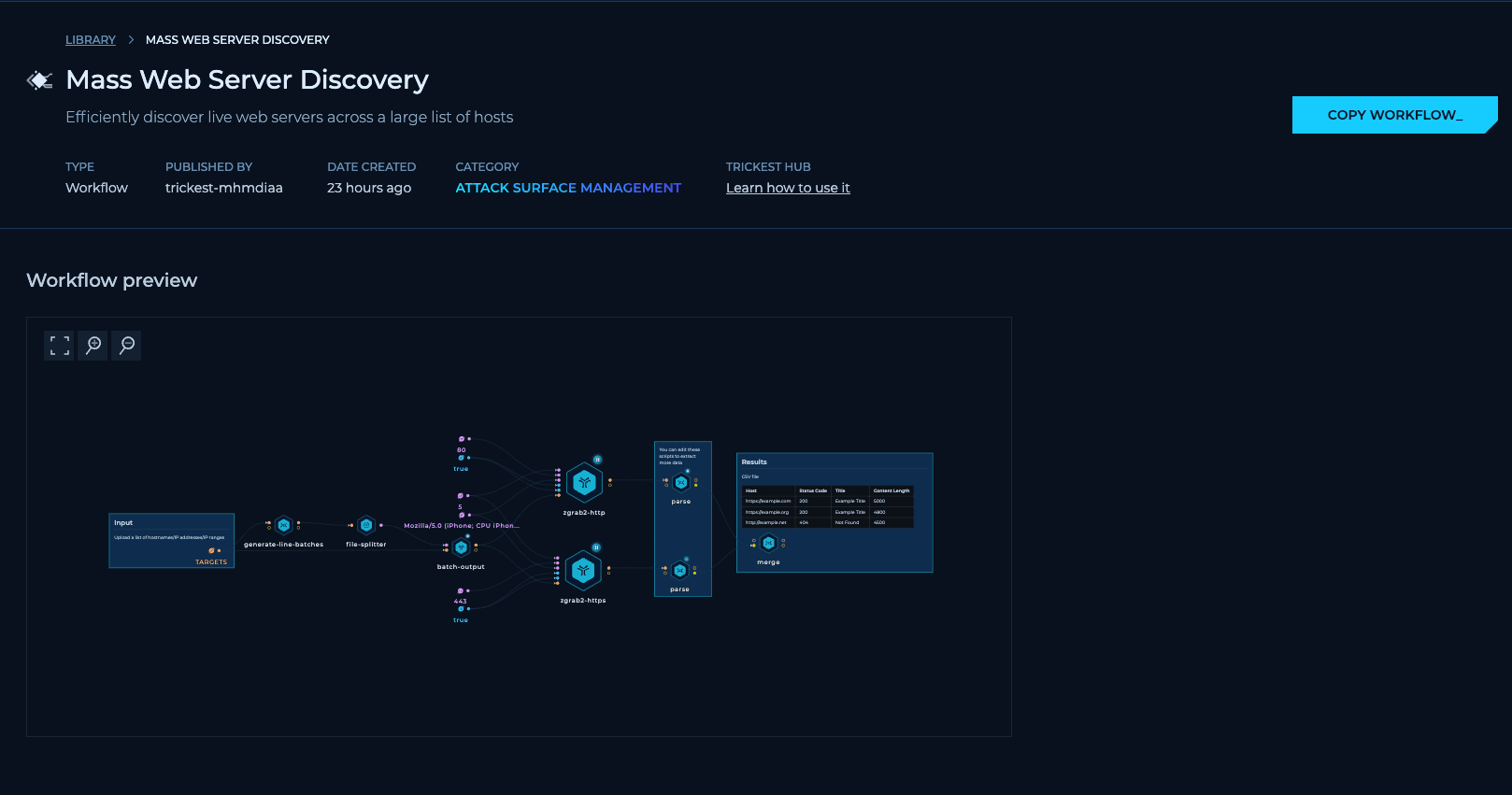
We mentioned that zgrab2-http may be used in a future update to the project to collect HTTP data in a similar way, but you don't have to wait. The workflow template we plan to use is already available in the library
This wraps up our exploration of cloud provider infrastructure mapping and its practical applications. We've had a closer look at the new trickest/cloud project, and walked through the process of building an efficient workflow, highlighting the research and design decisions involved.
All the workflows we've discussed today are accessible to every user through the Library. If you haven't already, make sure to sign up to Trickest. By doing so, you'll gain access to these workflows and a whole lot more!
Get a personalized demo
A 30-minute walkthrough. We map the platform to your stack and answer pricing and deployment questions for your environment.