loading
Loading content
loading
Per-asset ASM pricing treats a fluid surface as a fixed count - driving tier cliffs and surprise bills. See a better model that prices execution capacity.

Trickest · Security Team
TL:DR/Answer capsule
“Asset-based” pricing treats a fluid attack surface as a fixed count, so discovery noise and churn inflate what becomes billable.
Short-lived or decommissioned items can remain billable for a vendor’s observation window (often measured in days), skewing invoices.
Fixed asset tiers create cliffs - small overages can trigger large plan jumps and unpredictable budgets.
Stopping discovery at the cap is the worst failure mode; preserve discovery and right-size enrichment with a grace window.
Better fit: price execution capacity/parallelism (no asset caps), so tuning, parser fixes, and experiments don’t become line items… See Trickest pricing.
ASM vendors love to say it: “your attack surface is constantly changing,” “you need continuous monitoring,” and so on. But then, once you’re past the technical demo and move on to pricing, they ask you to treat that attack surface as a fixed range, a countable thing they can charge for. Kind of contradictory, isn’t it?
Asset-based pricing in cybersecurity doesn’t get nearly as much attention as it should. Organizations either end up overpaying or leaving parts of their attack surface uncovered. In this post, we’ll dig into insights from industry reports, vendor docs, plus some of the horror stories we’ve heard firsthand from Trickest customers currently using our ASM solution.
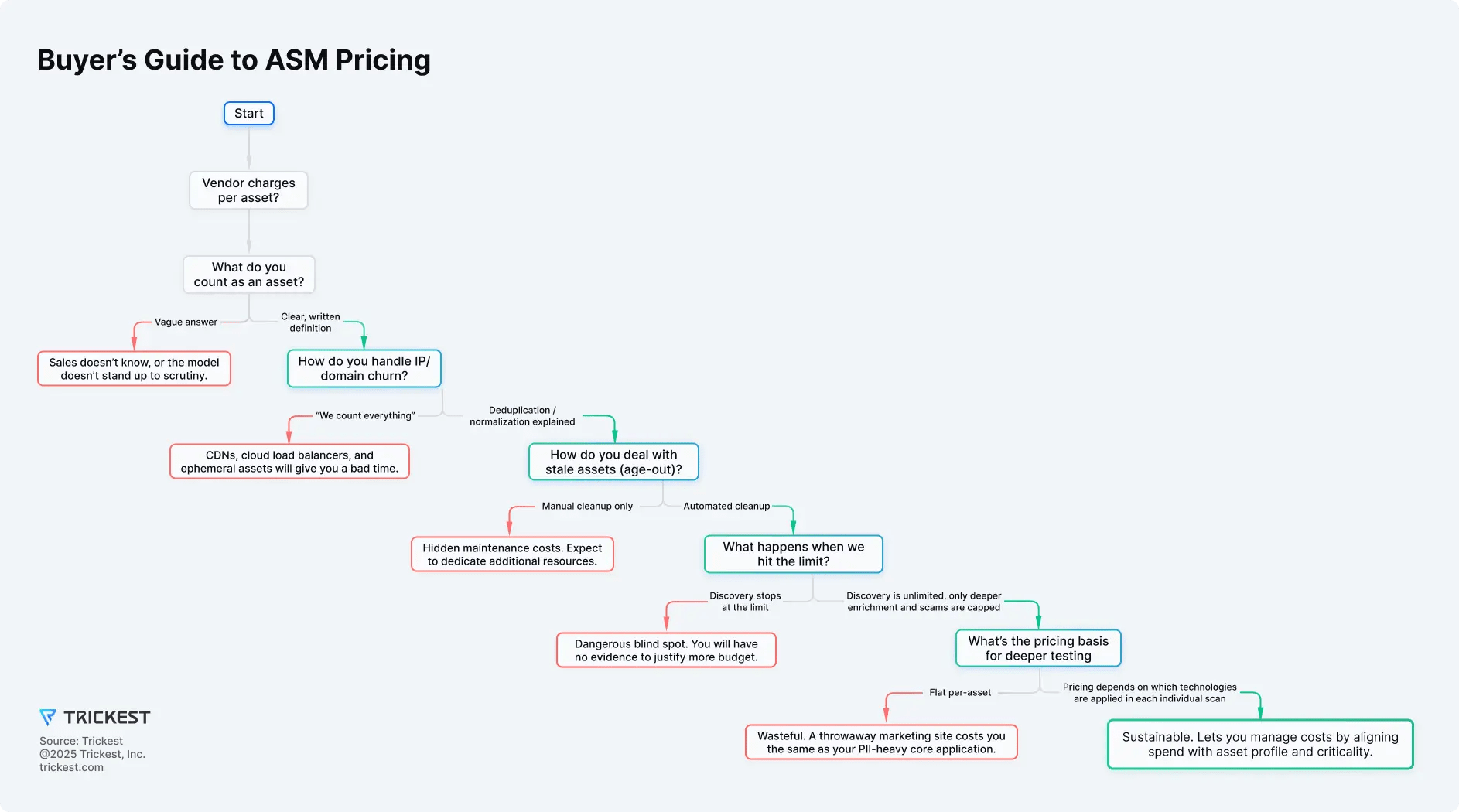
Figure 1. Start from coverage needs, then choose pricing that reflects execution capacity—avoiding per-asset penalties; see “Buyer questions” for PoC checks.
Is it an FQDN? An IP address? An open port? A TLS certificate? A cloud resource? Or some proprietary mix of all of the above? The answer depends entirely on the vendor. The same setup might be billed as a single asset by one provider and as five (or more) by another. Those definitions matter a lot when you’re budgeting for tens of thousands of so-called assets.
Some definitions are clearly worse than others. Counting raw IP addresses, for example, is very messy: in environments with CDNs, load balancing, and ephemeral resources, public IPs churn constantly. If every new IP is treated as a billable “asset,” your license count can balloon for reasons that have nothing to do with your real attack surface.
Another pitfall is how a vendor handles discovery scans in general. Attack surface management workflows are usually split into two phases: discovery (where you enumerate assets) and enrichment/scanning (where you collect more context and probe for security issues). Discovery can be inherently noisy and error-prone. If a product doesn’t properly deduplicate at this stage, you can suddenly end up with thousands of billable “assets” that all point to a few functional components, or in some cases, to nothing at all.
Both the Trickest team and our customers tune the discovery logic, and occasionally mistakes happen in the process. But customers are never charged for them - the out-of-the-box workflows and pricing protect us from noisy scans turning into line items.
The safer bet is vendors that normalize across multiple identifiers. But don’t assume. Always run a PoC with your trickiest edge cases. If the vendor’s definition of a billable “asset” doesn’t align with how your infrastructure really works, you need to know whether your budget will hold up or collapse under the mismatch. At least you’ll be making the choice with eyes open.
Let’s be generous and assume the asset definition actually matches your infrastructure (or the per-asset price is so low you don’t really care). Even in that best-case scenario, there’s a deeper problem: you’re still being asked to put a fixed number on something that refuses to stay fixed.
It sounds obvious, but most organizations shop for an ASM vendor precisely because they don’t know the full extent of their attack surface. And they’re right not to, especially if they have multiple business units, a history of M&A, a global presence with information silos, active development teams spinning things up in the cloud without strict controls, or all of the above. A Trend Micro global study shows nearly two-thirds of IT and business leaders admit they have blind spots in their attack surface. On average, organizations only estimate 62% visibility, and even that’s described as a “best guess”.
Locking yourself into an asset range up front almost guarantees you’ll be wrong. The attack surface is fluid. Even if you capture a reasonably accurate snapshot today, there is a chance it won’t reflect reality a quarter from now. Overestimating leads to unnecessary spending, while underestimating leaves real exposures outside the scope of monitoring.
Figure 2. Asset counts fluctuate; budgeting to a static per-asset number creates mismatched spend and blind spots.
How long does a short-lived marketing campaign site or ephemeral cloud instance linger on your bill? That depends entirely on the vendor.
Most vendors keep assets “alive” for an observation window (typically anywhere from 15 to 90 days). During that period, every asset that appears is considered billable, even if it disappears after only a few hours.
If your dev, devops, or marketing teams spin up ~1,000 assets per day and decommission them the next day, with a 90-day age-out period and no compensating measures, your bill may not reflect the 1,000 assets you actually have at any given time; it reflects 90,000.
Some vendors try to soften this by letting you manually delete assets from the platform when you decide they’re decommissioned. It’s slightly less painful than waiting out the retention window, but it shifts the burden of ongoing maintenance work onto your team, just to keep your license counts under control.
Many vendors sell asset tiers in big, fixed blocks. If your plan covers 1000 assets and you have 1100, you're bumped into the 5000-asset tier.
For organizations with tens of thousands of assets, an extra block may not hurt. But for small and mid-market companies, those jumps can be brutal, especially if crossing the line kicks you into an entirely different plan class (from mid-market/scale-up to enterprise).
The core problem is that "number of assets" is a crude and unreliable way to measure scale. Using it as the sole factor that determines when a customer gets forced into a new pricing band doesn’t make sense.
A healthier model at larger scales is either a fixed annual cost (predictable budgeting) or progressive pricing, where the effective cost per asset drops as usage grows. Both approaches align better with the technical reality that discovery and monitoring benefit from economies of scale, and they allow users to share in those efficiencies.
Usage spikes happen (sudden environment growth, new deployments, short-lived campaigns, what have you). How a vendor handles those temporary surges matters a lot.
Some vendors simply stop discovery the moment you hit your cap. That’s the worst-case scenario: you lose visibility into what’s being added to the attack surface, and you also lose the evidence you’d need to justify buying more capacity. It’s a perfect lose-lose situation; frustrating for the user, and ironically, it makes upselling harder for the vendor too.
A healthier approach is to give customers a grace period to see if the spike normalizes, and only pursue an upsell if the attack surface growth seems permanent. Even then, vendors should scale back enrichment and scanning first, not discovery itself. Discovery should be the last thing to stop. When discovery stops, you don’t know what’s being left out, how risky it is, or what case to make for more coverage.
Low per-asset pricing might look attractive. A few dollars per asset feels harmless even if you’re over-provisioned. But there’s no free lunch. Every attack surface management platform balances a set of technical levers and tradeoffs that determine how much coverage it can provide and at what price. The more you understand those tradeoffs, the better you can judge what that pricing truly means.
From our perspective, coverage is driven by four main factors:
Breadth/Assets - what you cover. The number of root domains, FQDNs, IP addresses, ports, certificates, DNS records, cloud services, etc.
Depth/Techniques - how you check. OSINT and passive discovery, active probing, port scans (and which ports you choose), secret detection, content discovery, version-based CVE scanning, benign exploits, fuzzing.
Frequency - how often you revisit. Continuous, hourly, daily, weekly, monthly, or on demand.
Execution power - how much compute you need. More workers in parallel mean shorter, more frequent revisits without sacrificing breadth or depth.
And all of that rolls up into Time-to-Coverage - the wall-clock duration to achieve your intended coverage on a given asset set. The shorter the Time-to-Coverage, the more flexibility you have: cover more assets, apply more techniques, increase frequency, or reach the same coverage with less execution power.
The first three levers - assets, techniques, and frequency - are mostly dictated by your threat model. You can’t meaningfully shrink the number of covered assets without introducing blind spots. You can’t cut techniques without reducing depth. And you can’t safely lower the frequency on critical, fast-changing assets without adding risk.
Execution power, the fourth factor, is where vendors bear real operating costs. It scales with how many assets they cover, how many techniques they run, and how often they repeat the process. Because Time-to-Coverage is a consequence of these choices, pricing that ignores execution power usually hides compromises elsewhere.
Figure 3. Breadth, depth, frequency, and execution power together determine time-to-coverage - the practical measure of how fast planned coverage is achieved.
So when you see pricing that seems too good to be true, it probably reflects hidden compromises. Vendors can’t sustainably deliver full breadth, depth, and frequency without paying for execution power. If the business model doesn’t add up, chances are at least one of those other factors has quietly been lowered.
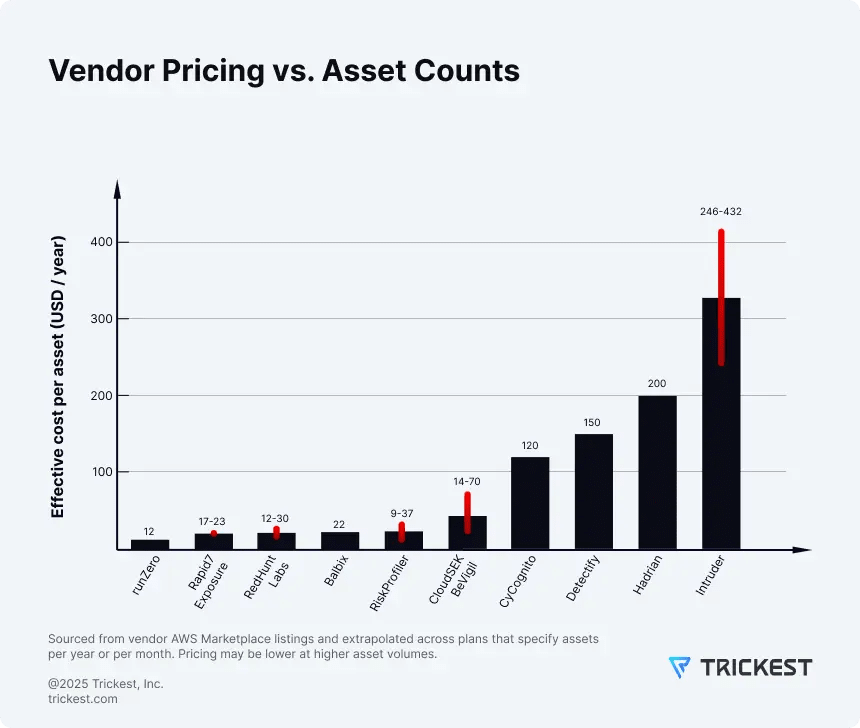
Figure 4. Per-asset pricing doesn’t scale linearly - similar asset counts can produce very different bills across vendors due to definitions and tiers.
Build on the levers above. Use breadth, depth, frequency, and execution power to structure the conversation. Instead of treating your entire attack surface as one uniform set of assets, segment it into tiers that reflect business value and technical profile. A critical web app deserves deeper, more frequent testing than a throwaway marketing campaign site; and there’s no point wasting cycles trying to port-scan an S3 bucket’s IP address.
Here’s a simple operating model:
Targets: everything.
Techniques: passive discovery, lightweight probes.
Frequency: continuous.
Time-to-Coverage: seconds per target.
Execution power: low.
Targets: risk groups and technical profiles.
Techniques: enrichment + targeted scans; regressions.
Frequency: hourly or weekly, based on sensitivity.
Time-to-Coverage: minutes to hours.
Execution power: moderate, scheduled.
Targets: high-value systems or after major changes.
Techniques: deep scans, full service discovery, DAST.
Frequency: event-driven or weekly/monthly.
Time-to-Coverage: hours to days.
Execution power: high, in bursts.
Use Fig. 1 - Buyer’s Guide to ASM Pricing during scoping; verify these in the PoC:
With Trickest you get ready-to-run ASM & other solutions, with tailored deep customization, and no asset-based caps. See Trickest pricing.
Counting assets is the wrong mental model to think about attack surface management. Attack surfaces are dynamic, and forcing them into fixed counts can result in blind spots, wasted spend, or both. Until vendors adapt, treat per-asset pricing as a warning sign and be clear on exactly what you’re paying for.
Get a personalized demo
A 30-minute walkthrough. We map the platform to your stack and answer pricing and deployment questions for your environment.