loading
Loading content
loading
Build an IDOR testing workflow that sends GET requests as three user types and reports matching status codes and content length.

Nenad Zaric · Co Founder & CEO
Protecting sensitive information stored on web applications has become increasingly important in today's digital age. However, many organizations are still vulnerable to security threats such as Insecure Direct Object Reference (IDOR) vulnerabilities. IDOR occurs when a web application exposes direct access to sensitive resources using predictable and easily guessable parameters, such as IDs, in URLs.
For instance, a URL like https://example.com/user/123 may reveal information about user 123. If a malicious actor can guess or increment the user ID in the URL, they can access confidential information. This vulnerability can lead to data breaches and financial losses for organizations.
Companies must implement strict security measures and regularly conduct security assessments to prevent these attacks. This blog post will delve into the dangers of IDOR vulnerabilities and show how organizations can identify and remediate these types of security flaws in their web applications. By implementing the proper automation, companies can protect their sensitive information and avoid devastating consequences.
To test API for the IDORs, we need to have a list of API endpoints. This can be done by various techniques, which we will cover in the next blog posts.
To execute endpoints immediately, we can copy them from Burp, spidered/crawl data, or through the OSINT tools.
This is the example data:
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/campaigns
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/campaigns?limit=1000
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/campaigns?limit=20
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/experiments
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/mobile_apps
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/premium_content_bundles
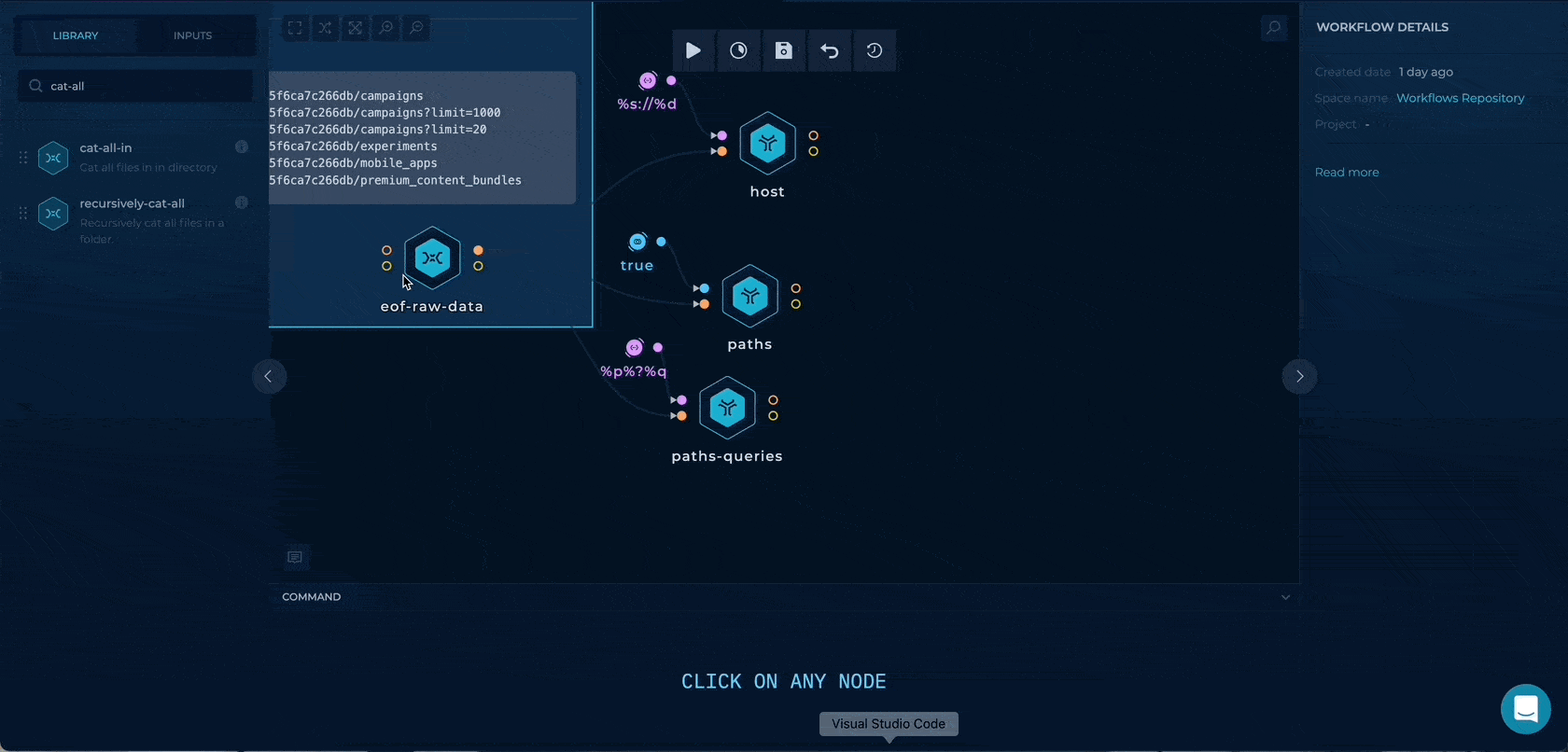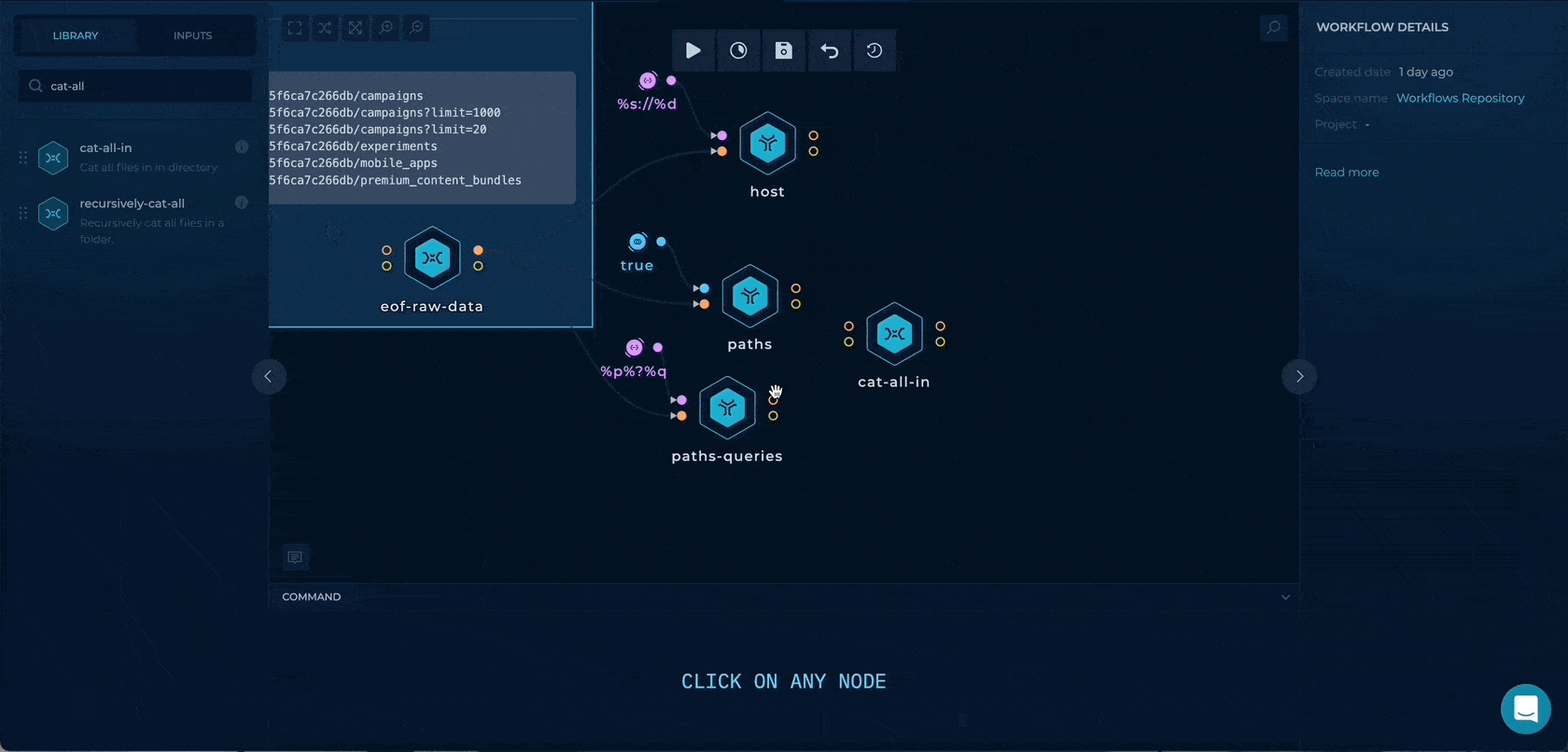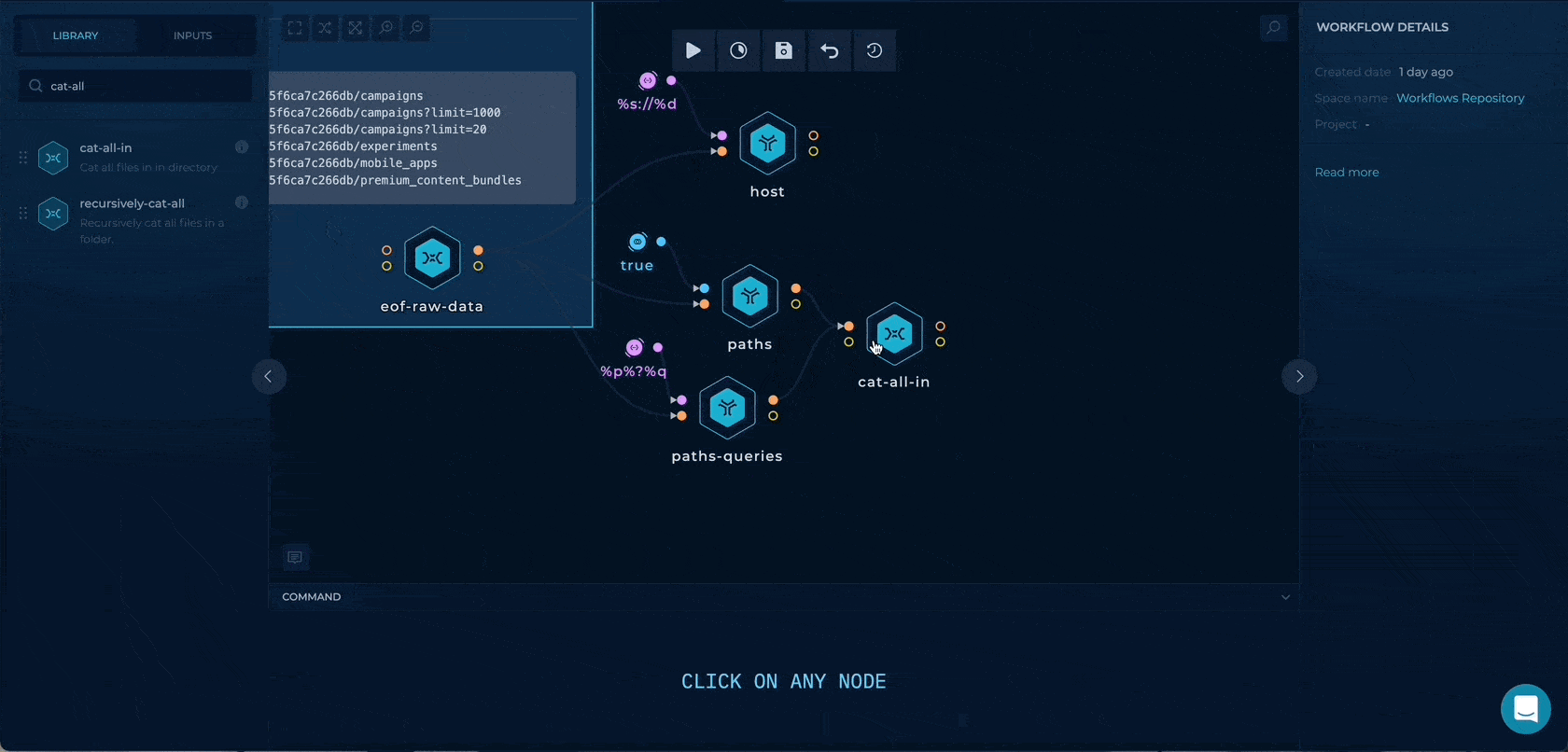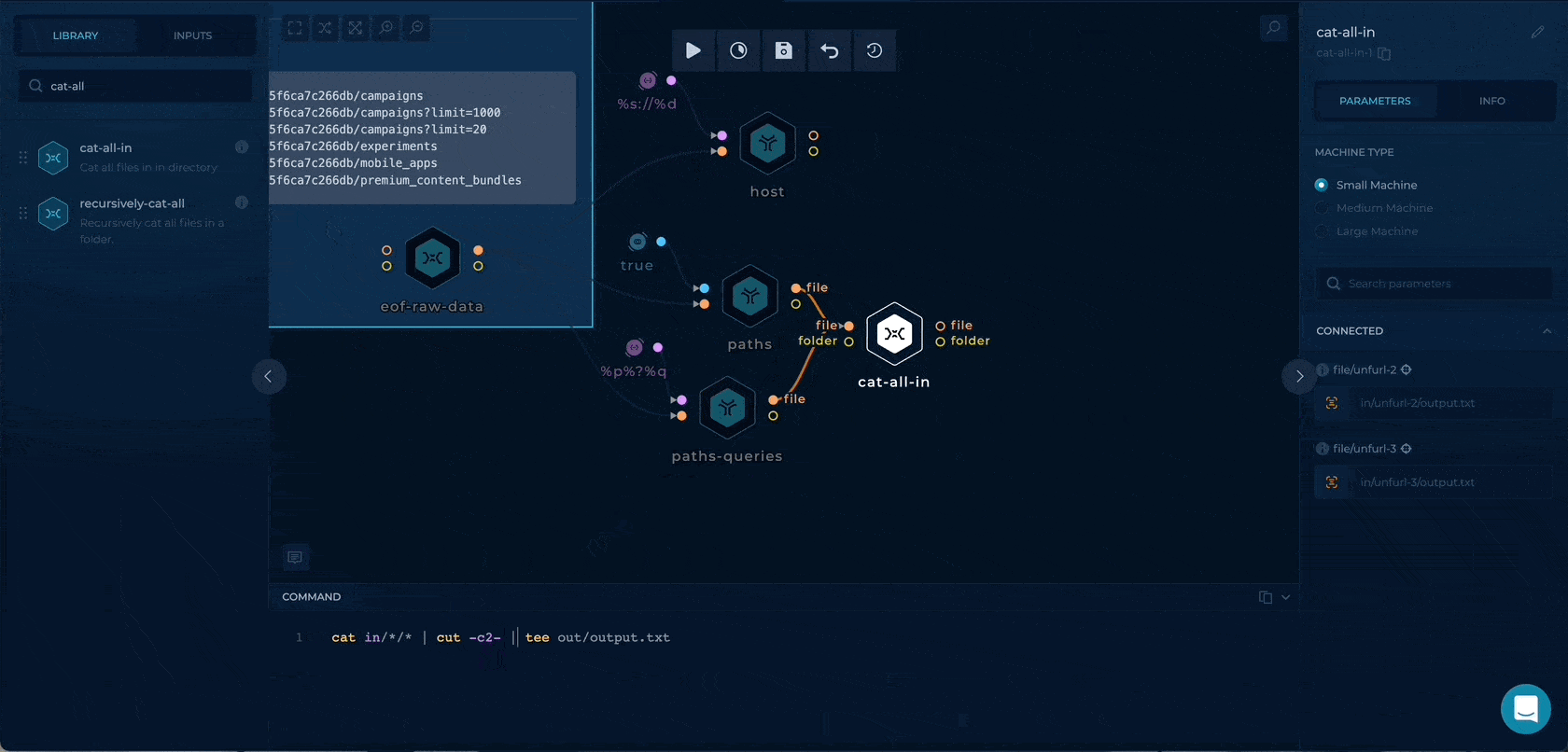
We will drag & drop an eof-raw-data node where we can paste the URLs directly.
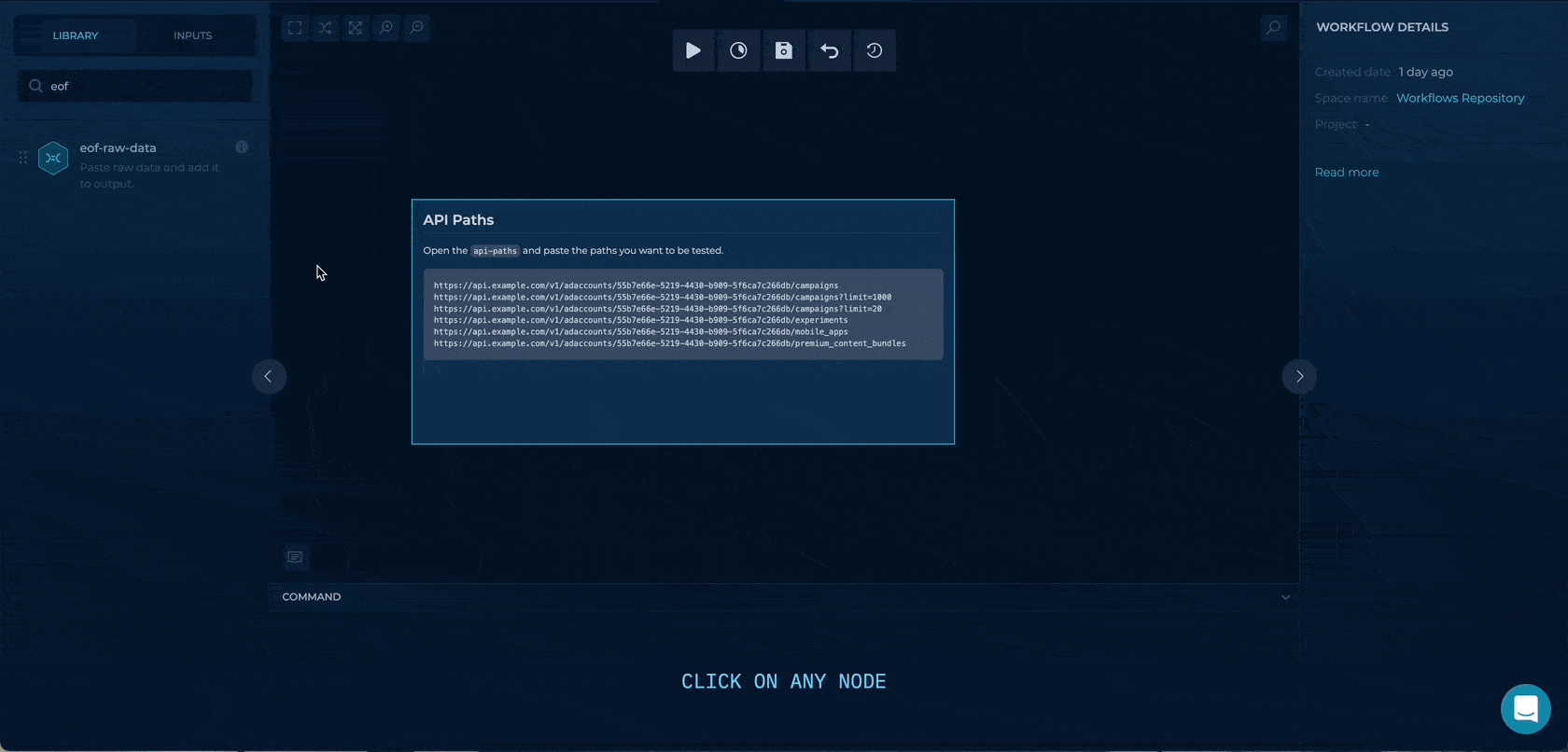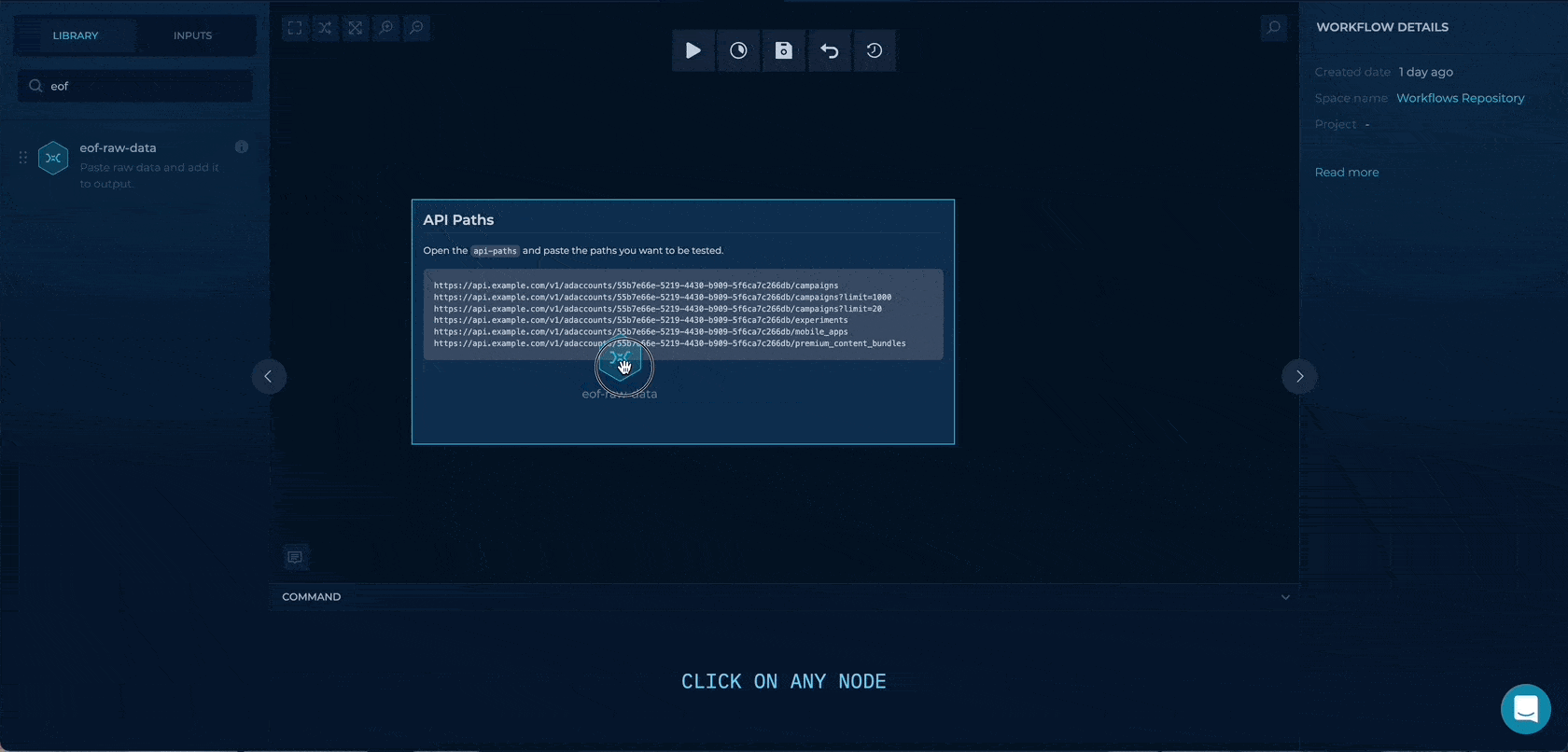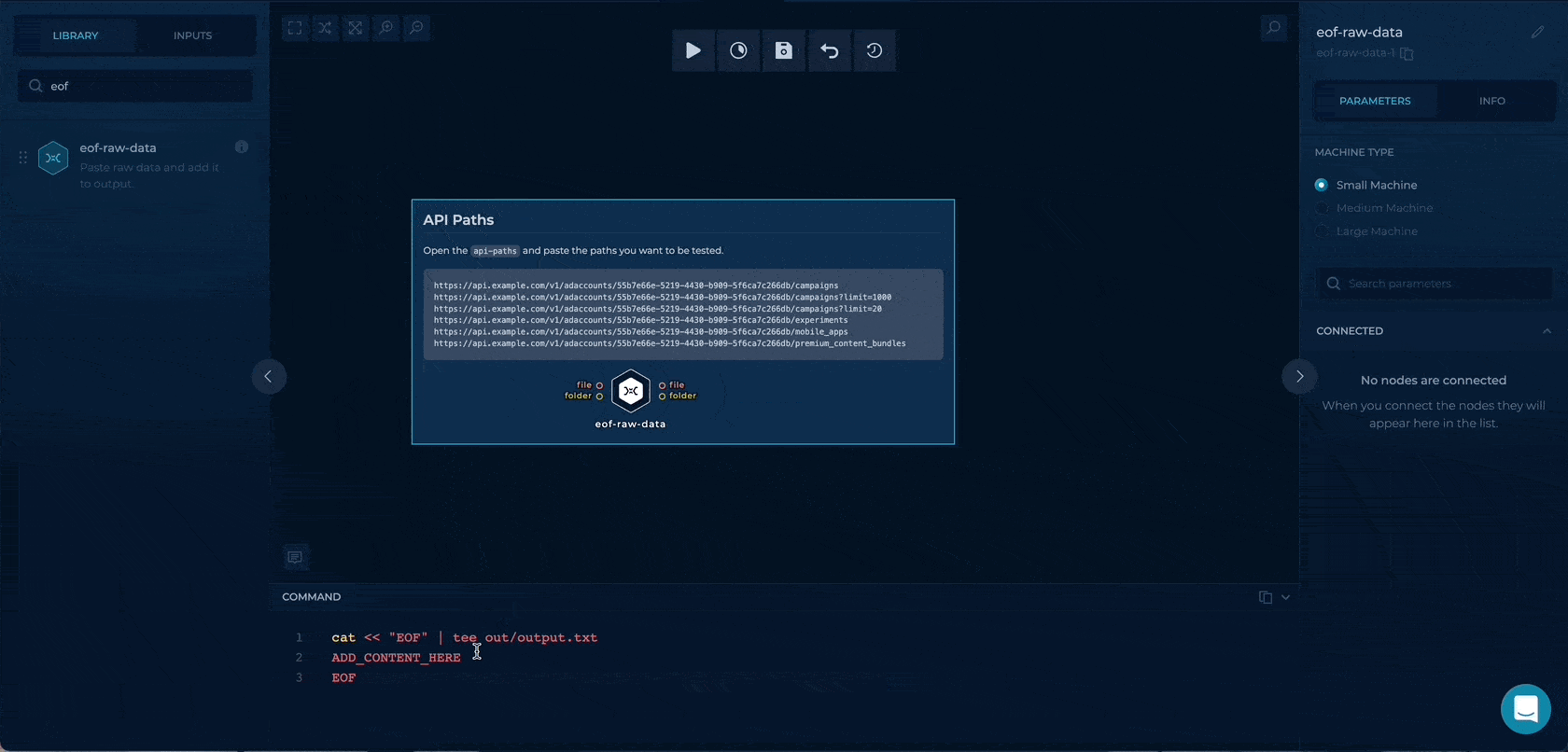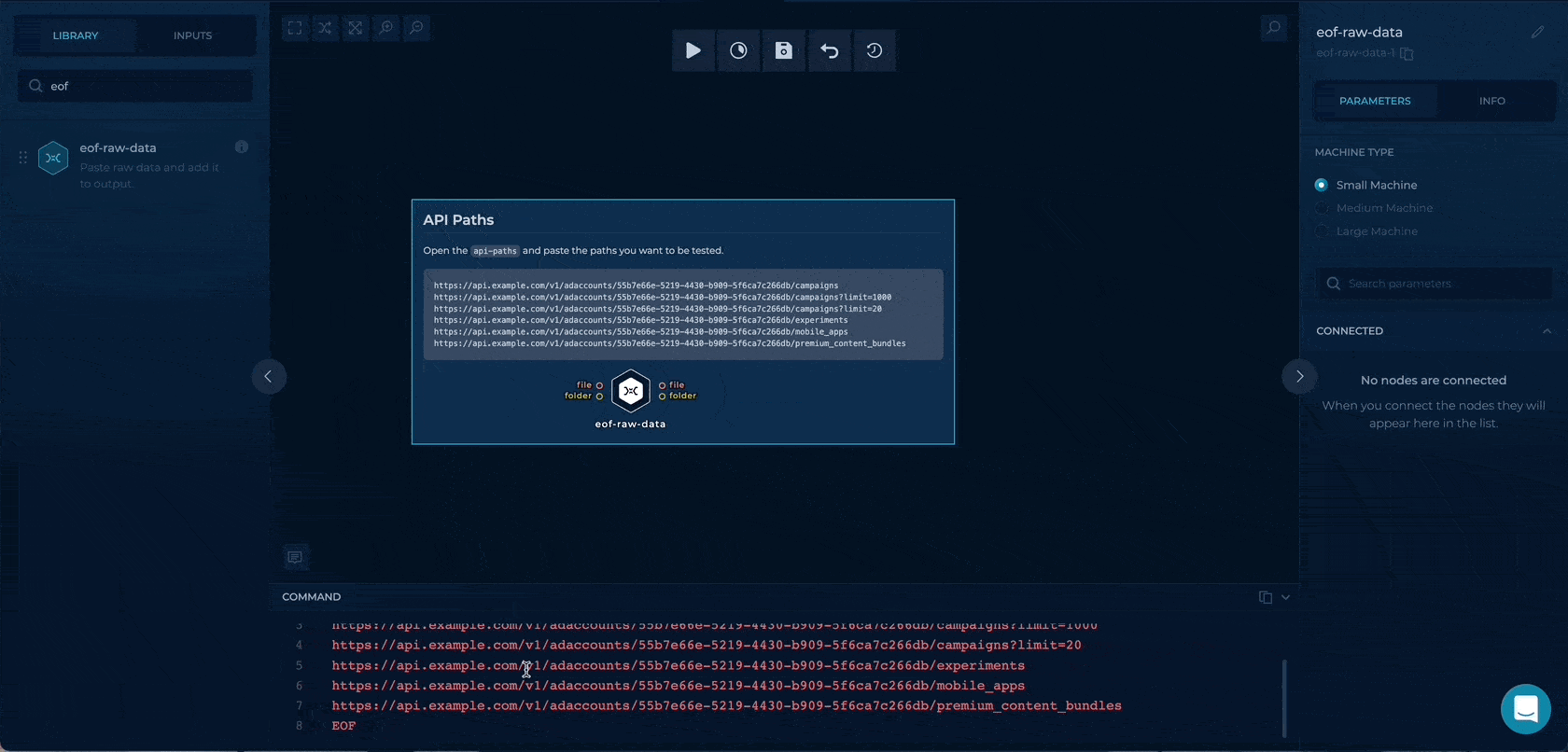
This node will output all of the URLs to the out/output.txt or the file output on the node.
Having the URLs, we can separate the data by types to be used as different file inputs later. We can use an awesome unfurl for this.
We will extract three types of data:
https://api.example.com)/v1/adaccounts/)/v1/adaccounts/?id=something)By using the %s://%d for custom parameter in unfurl we can extract the https://api.example.com to be used as hosts input
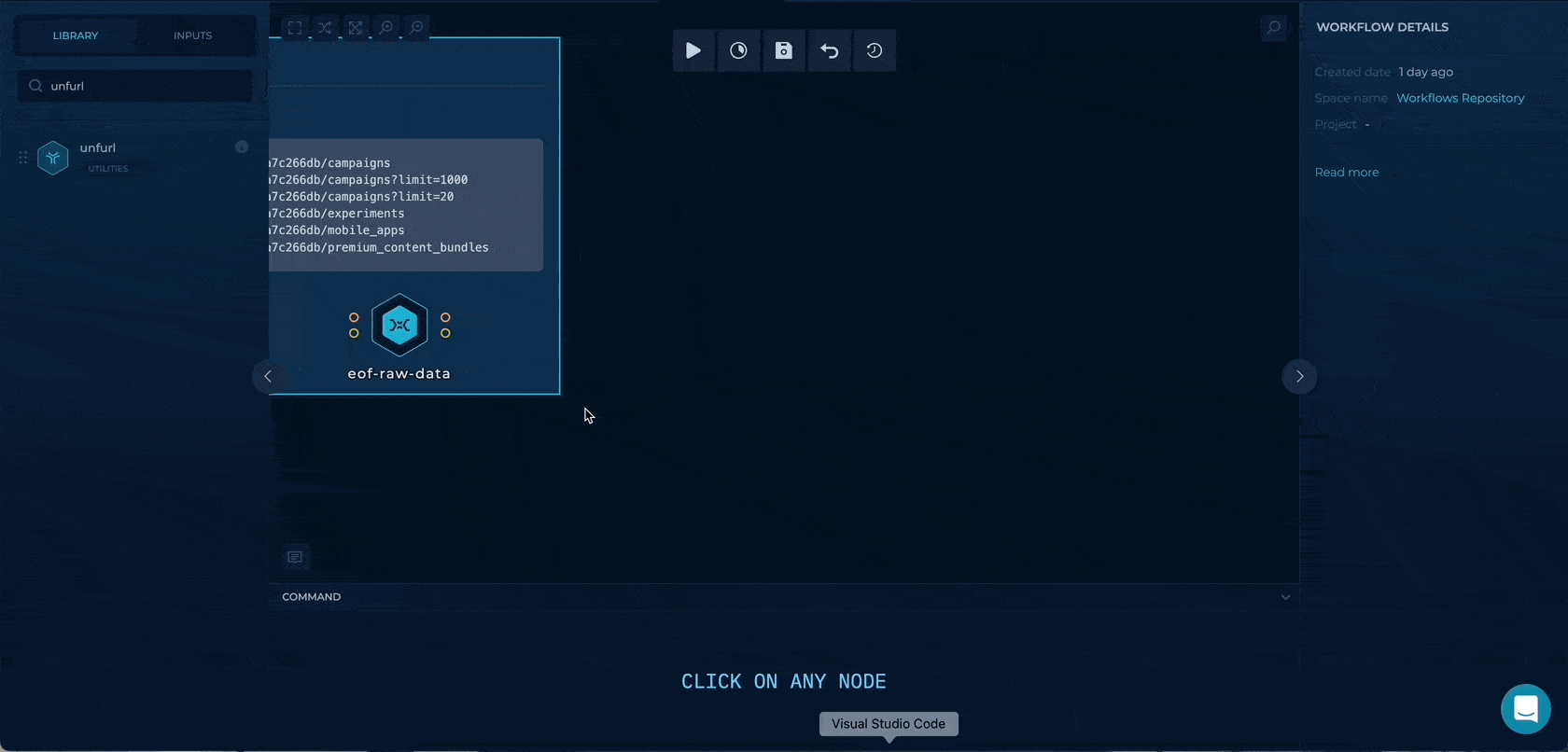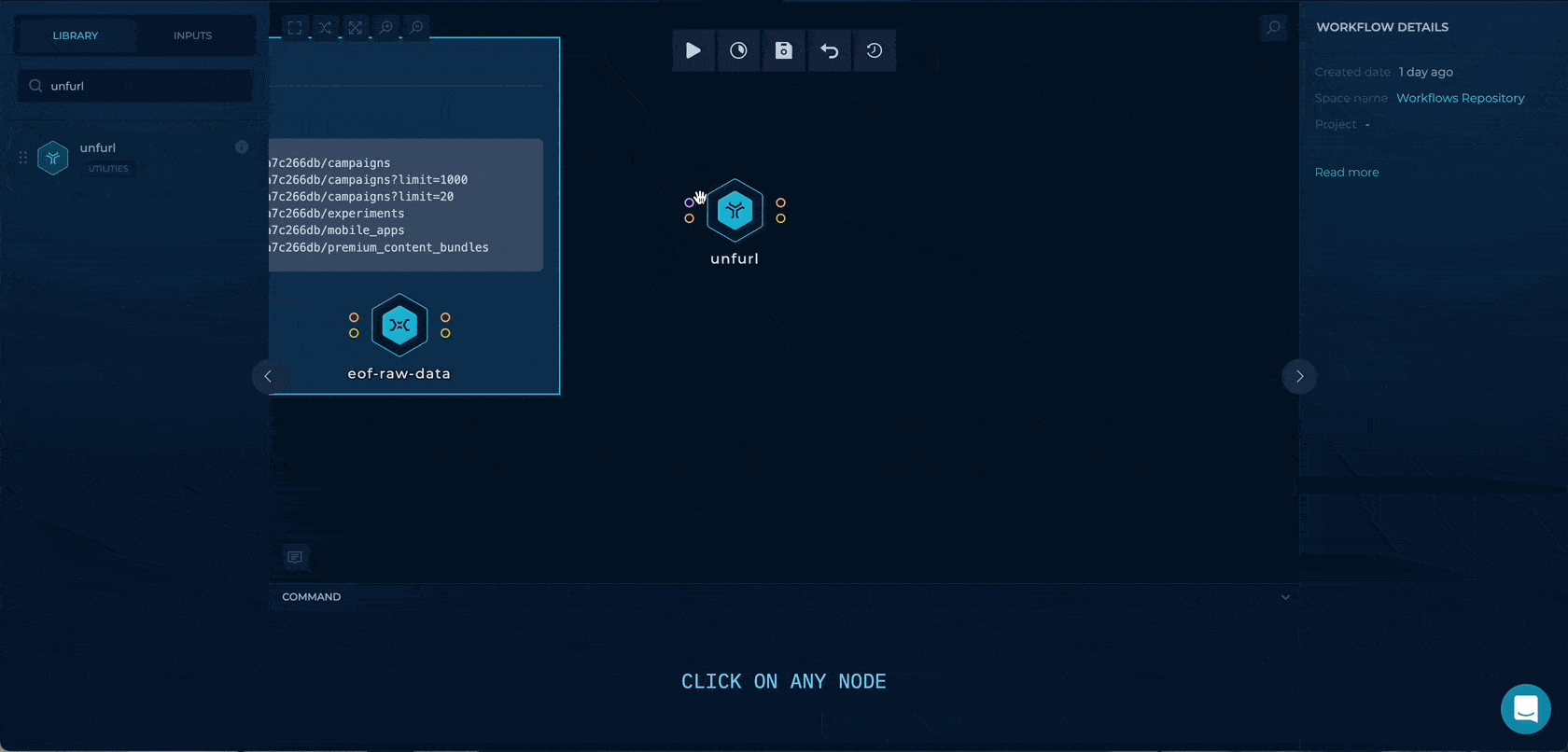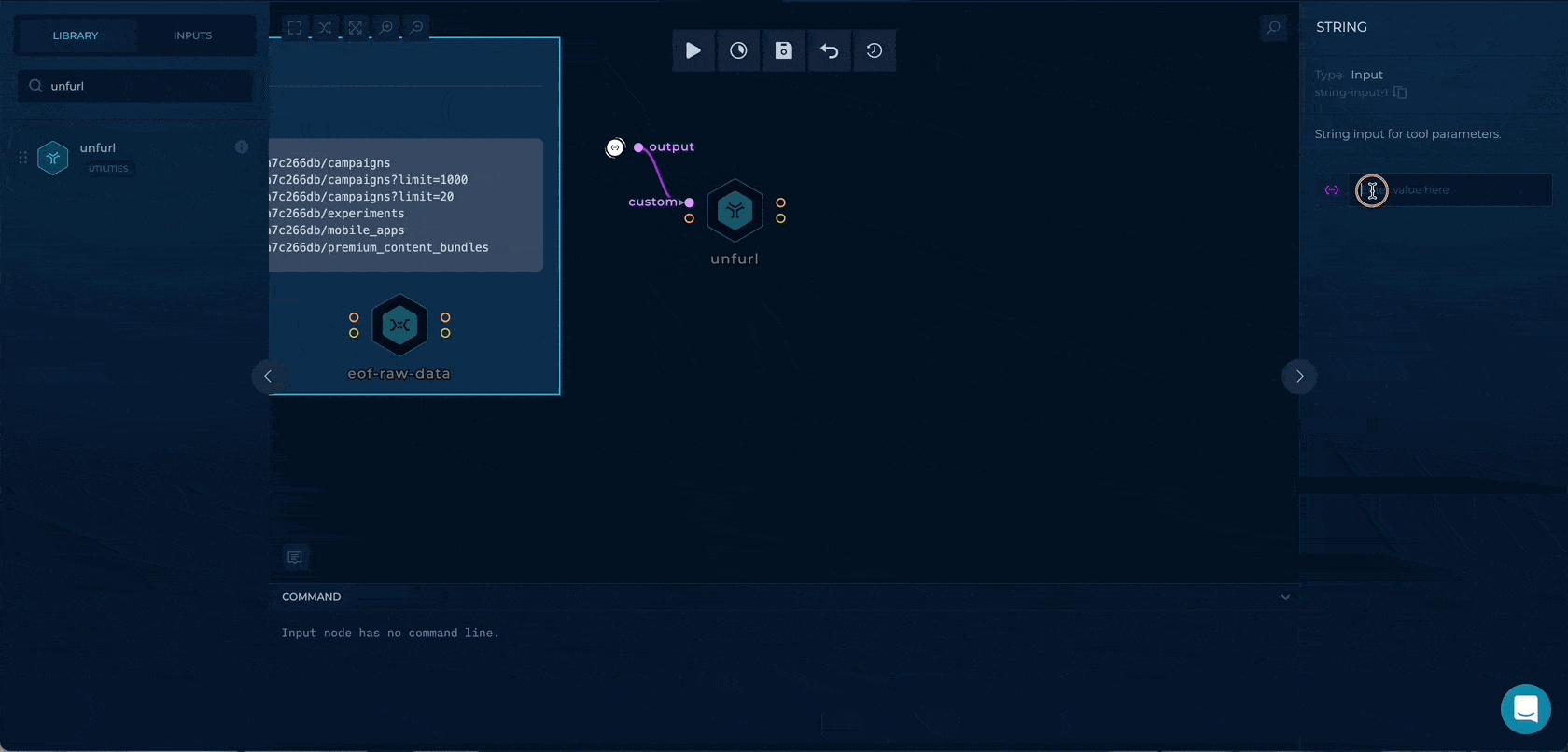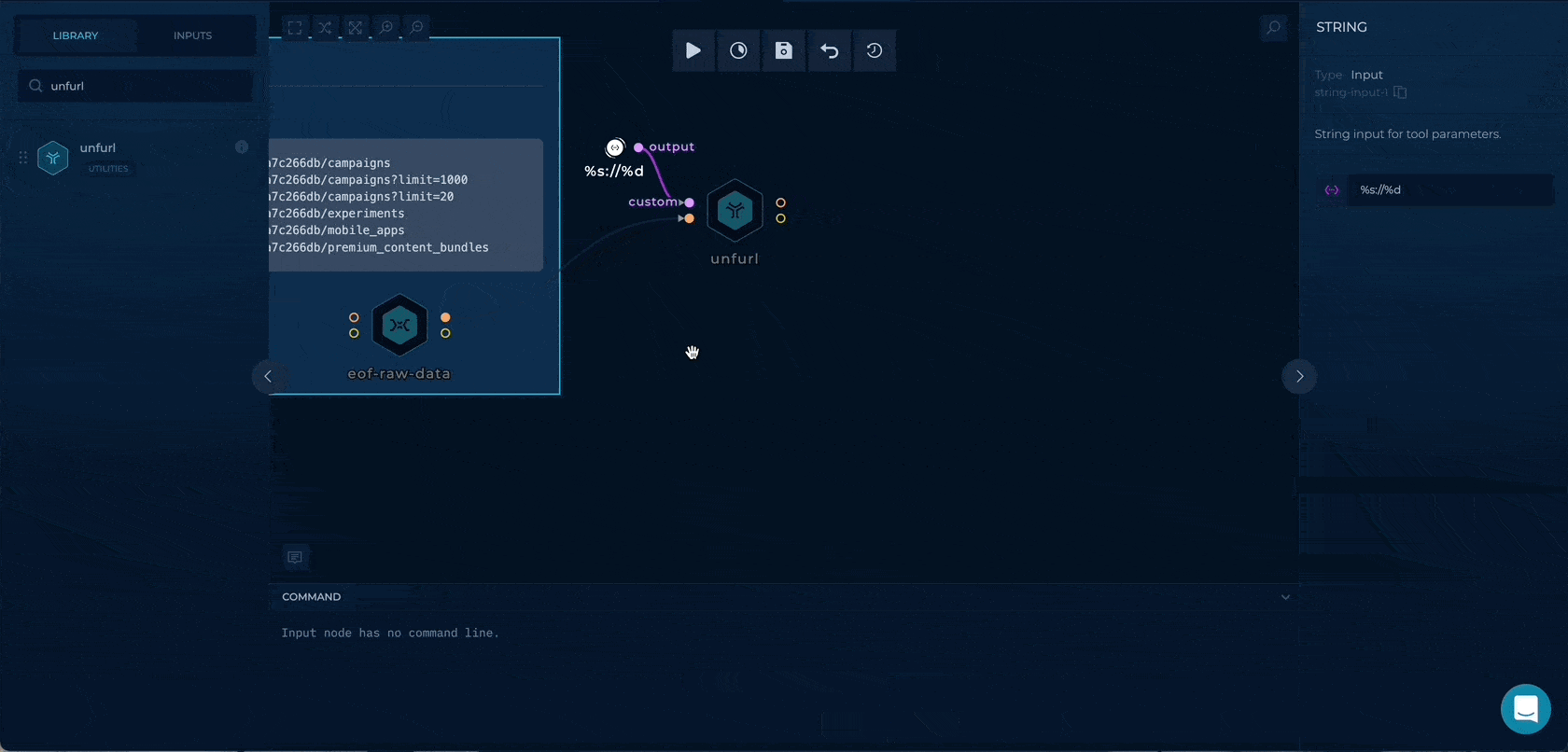
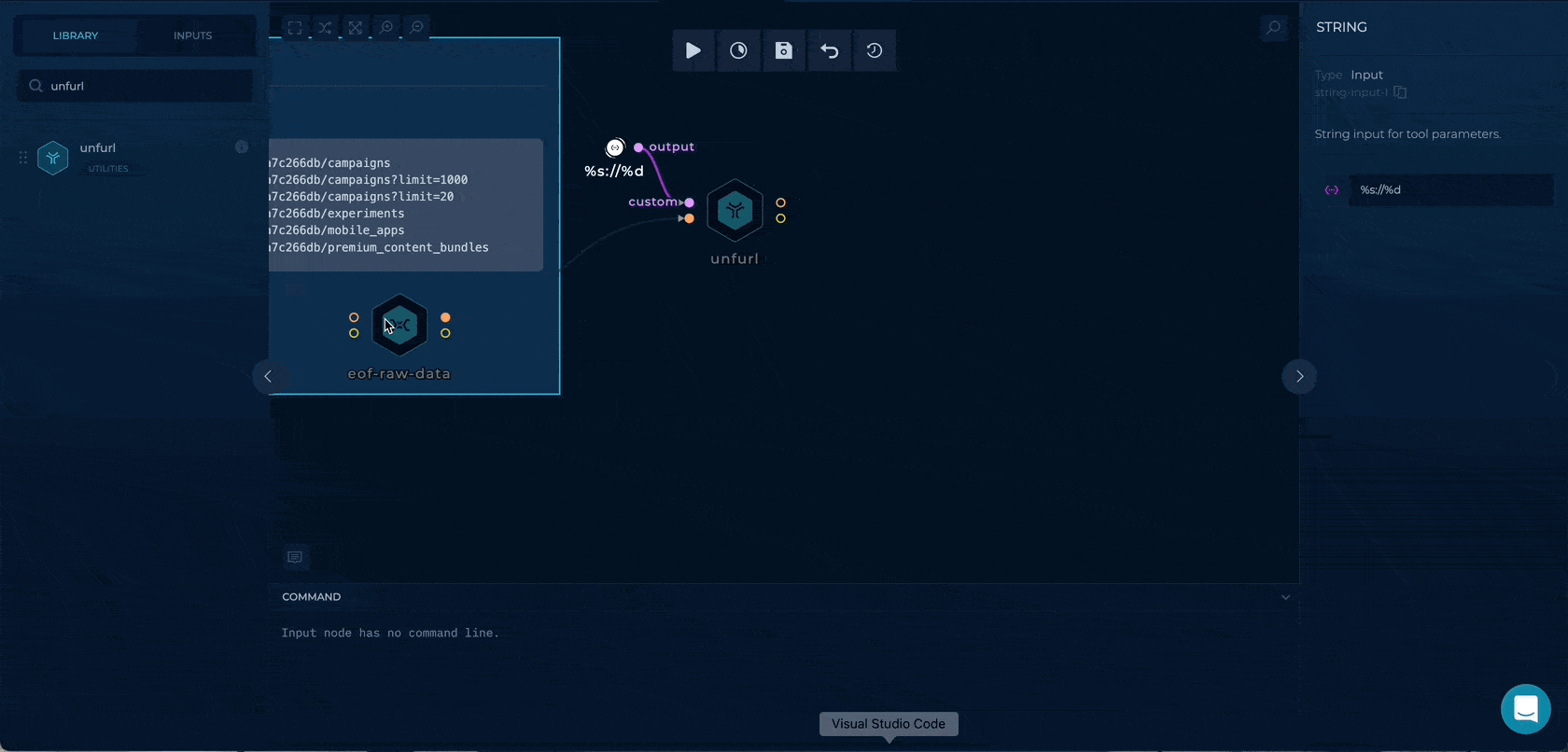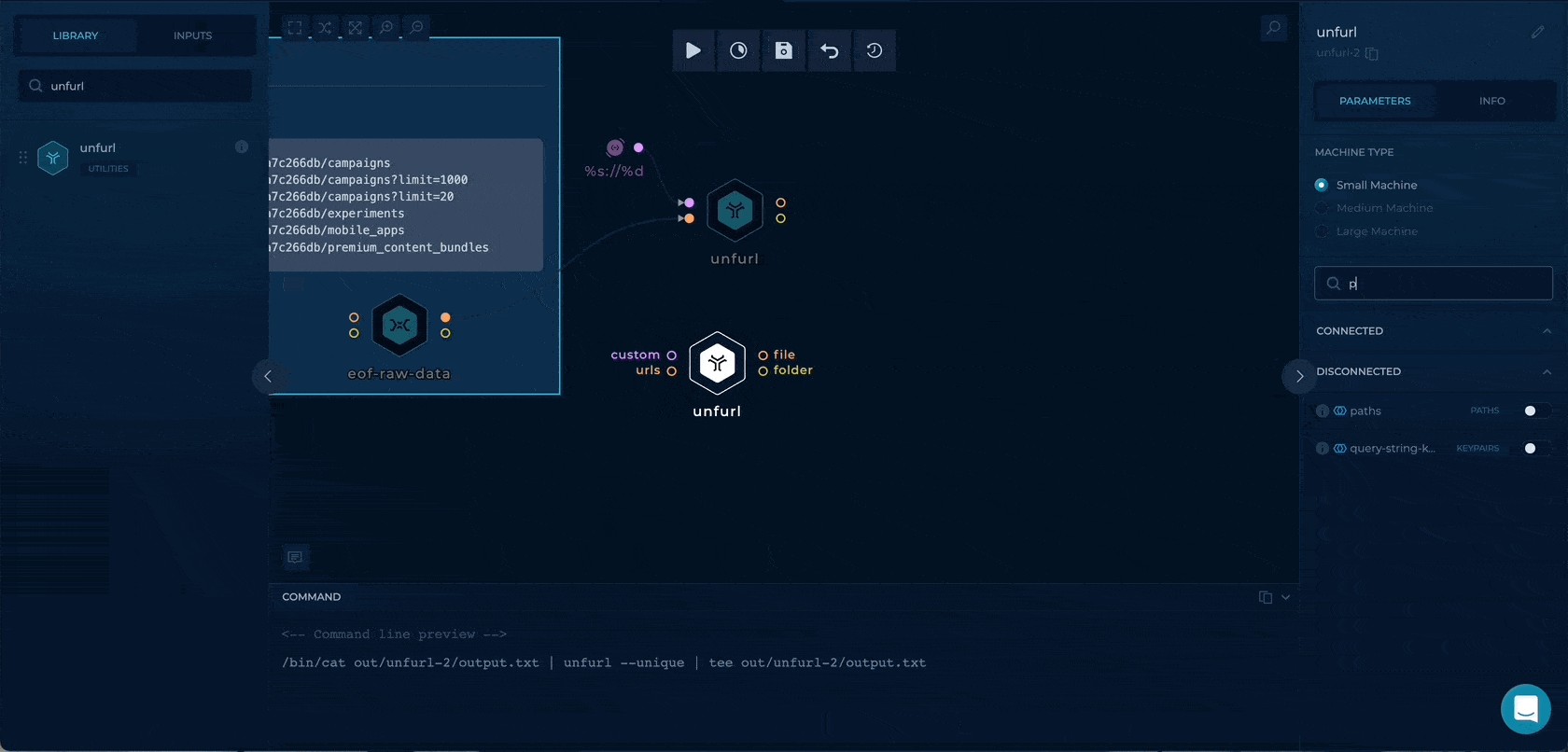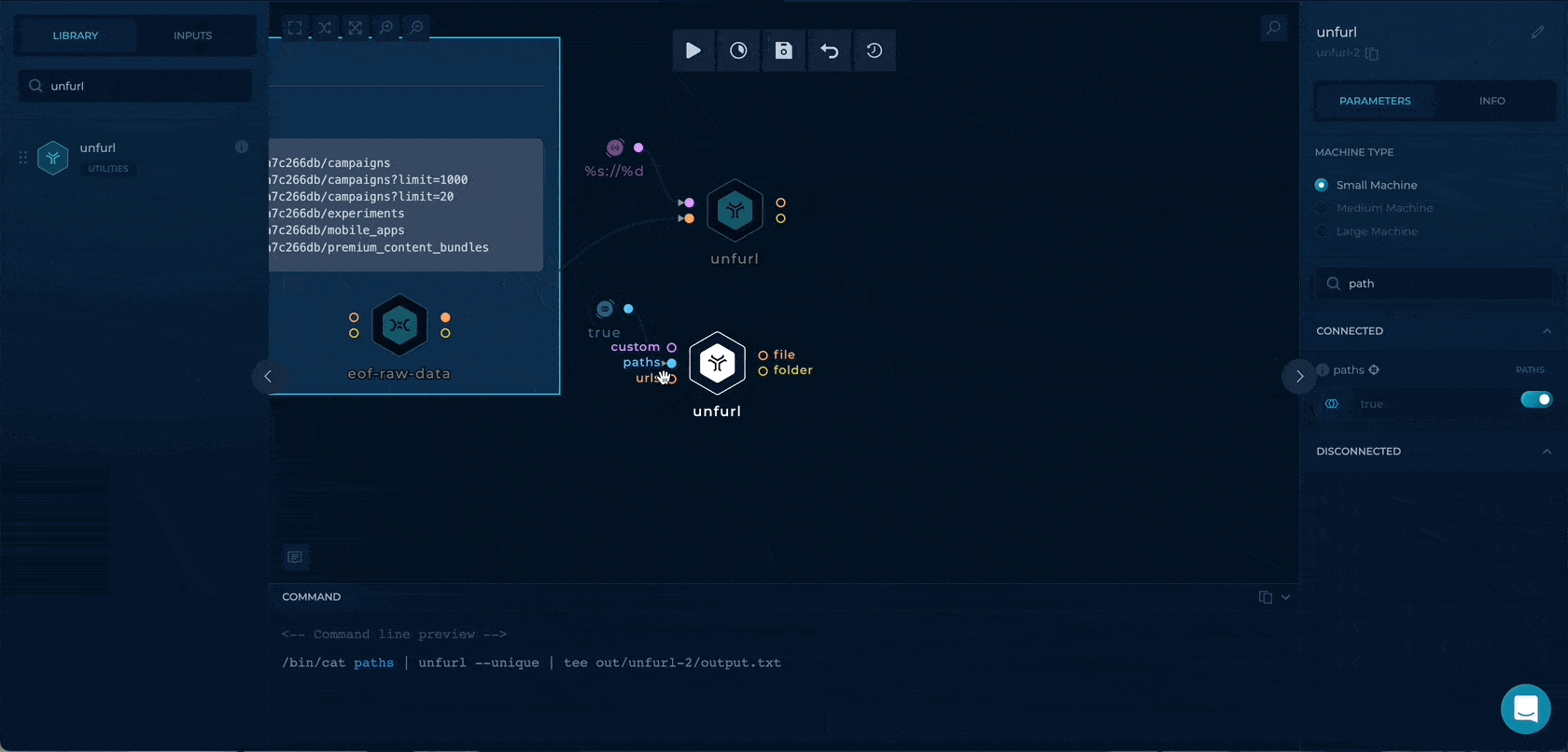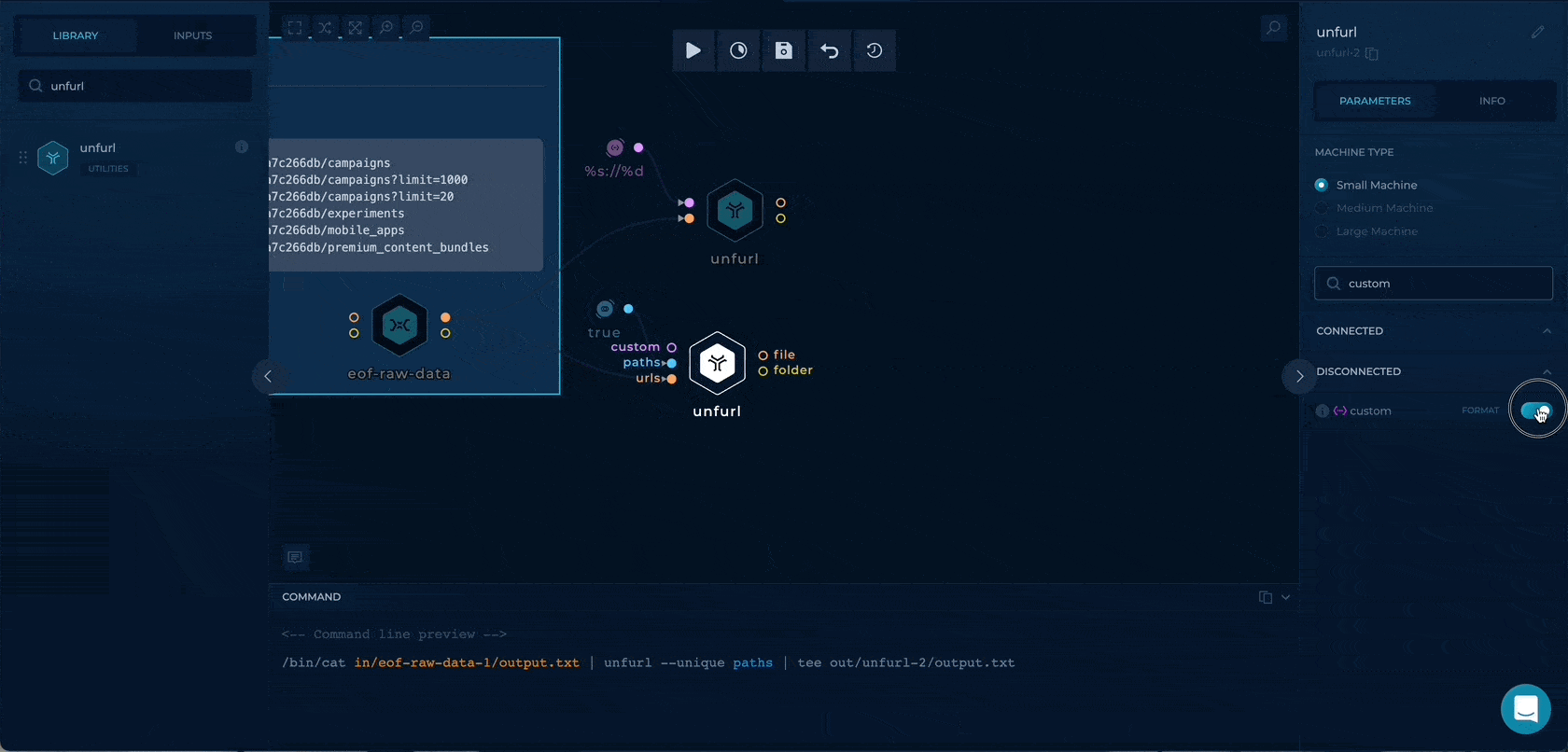
We can enable the paths boolean flag to enable only path extraction through unfurl. By getting the only paths here we will have wider testing as we will also check the paths (/v1/adaccounts) without any query parameters.
Using the %p%?%q, we can extract the path + query strings to be used as wordlists input.
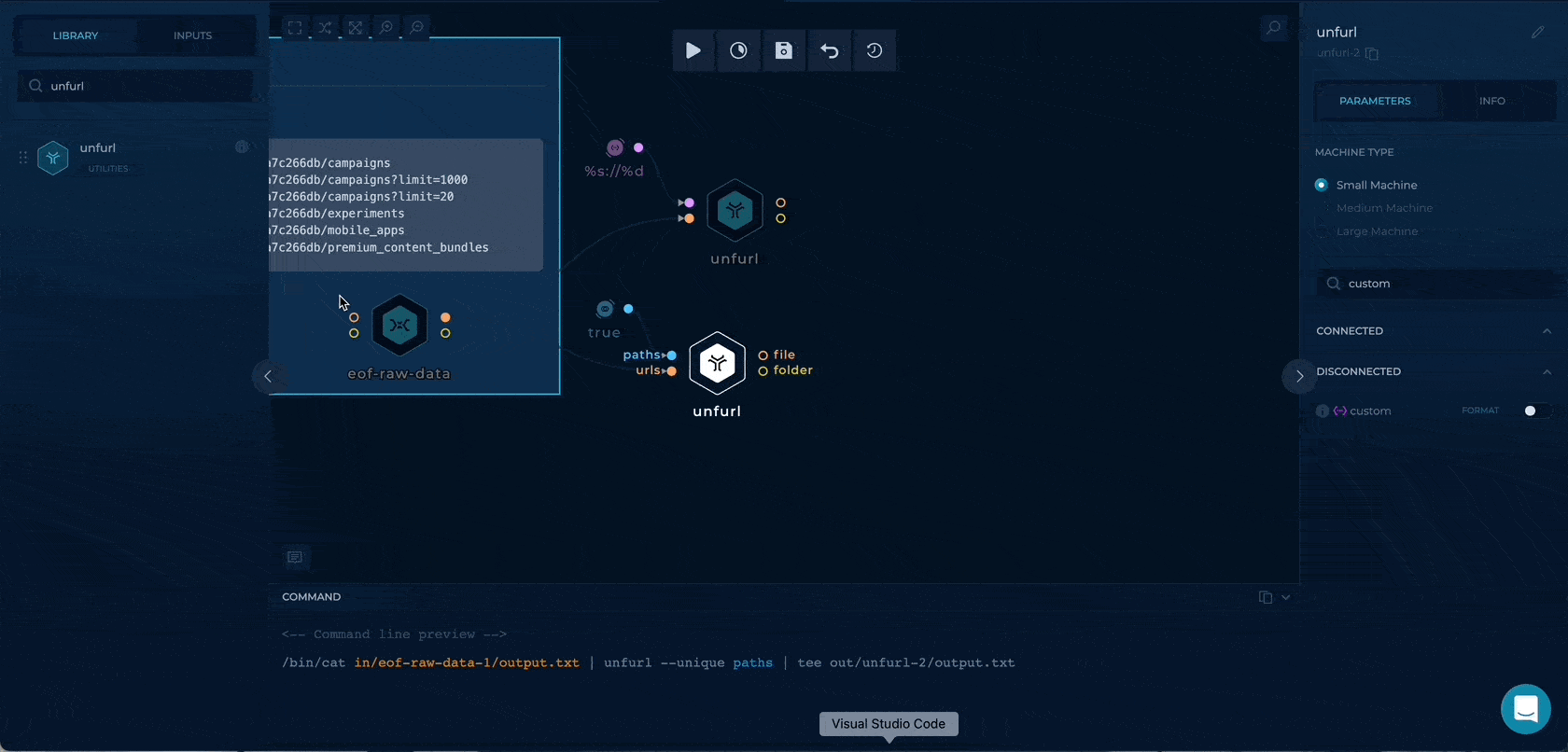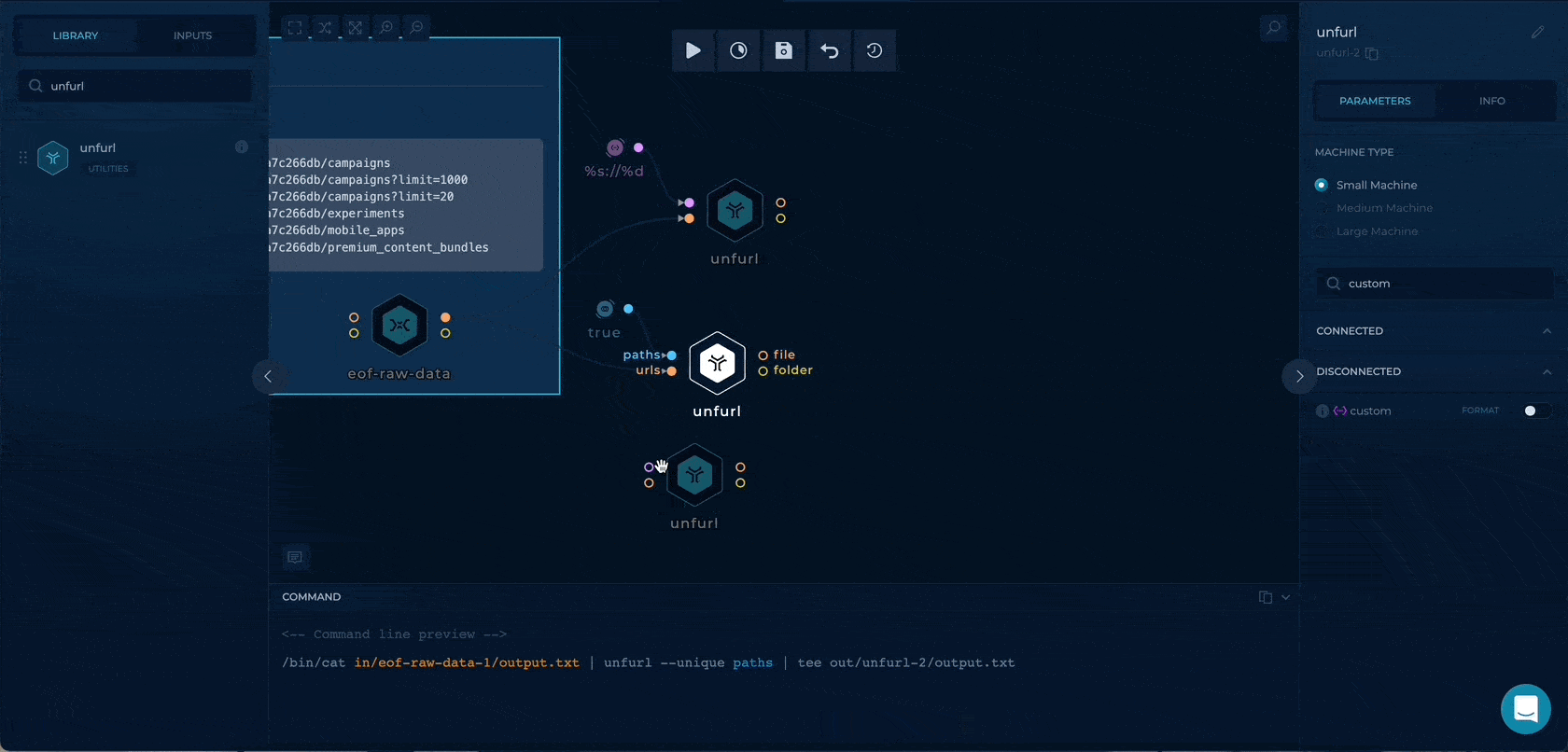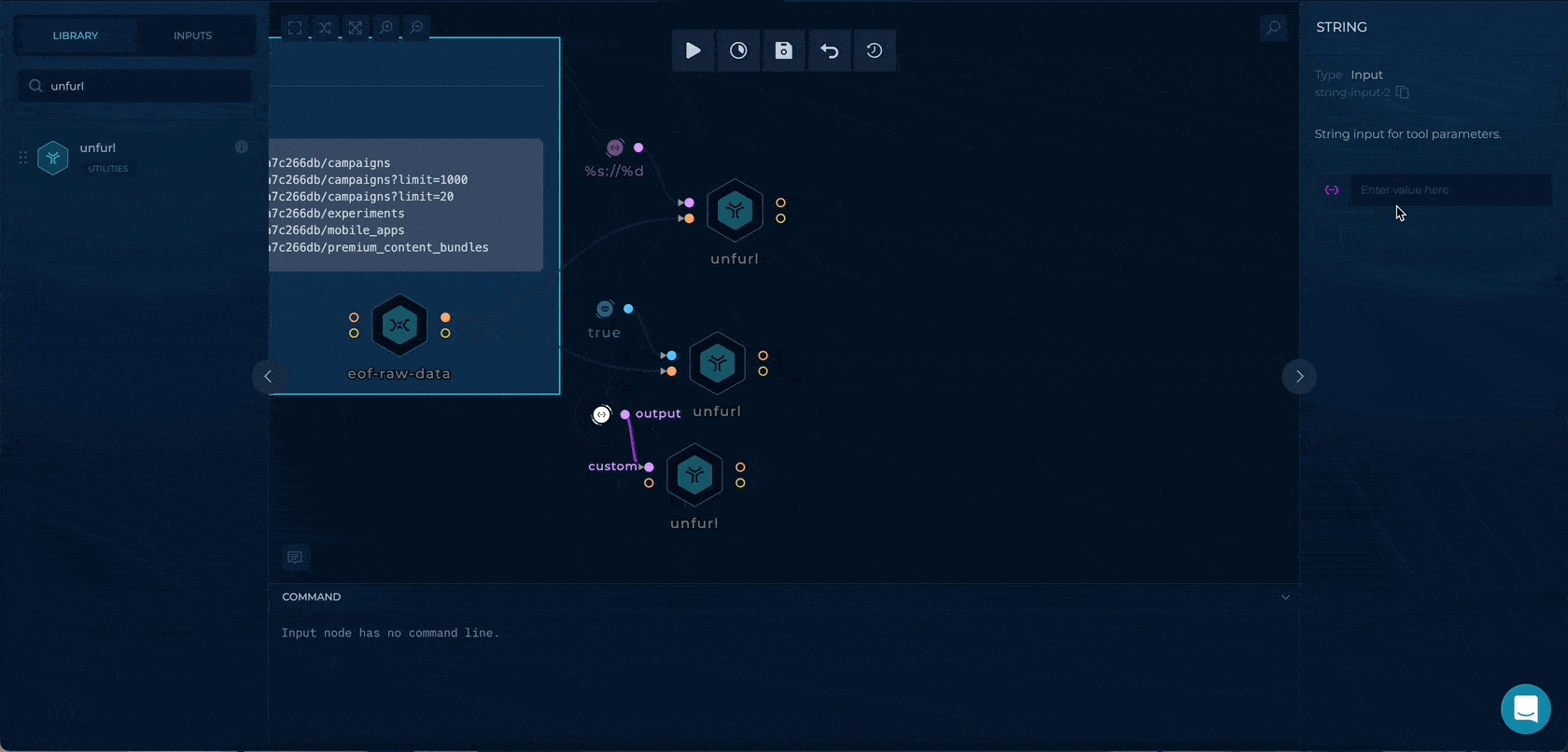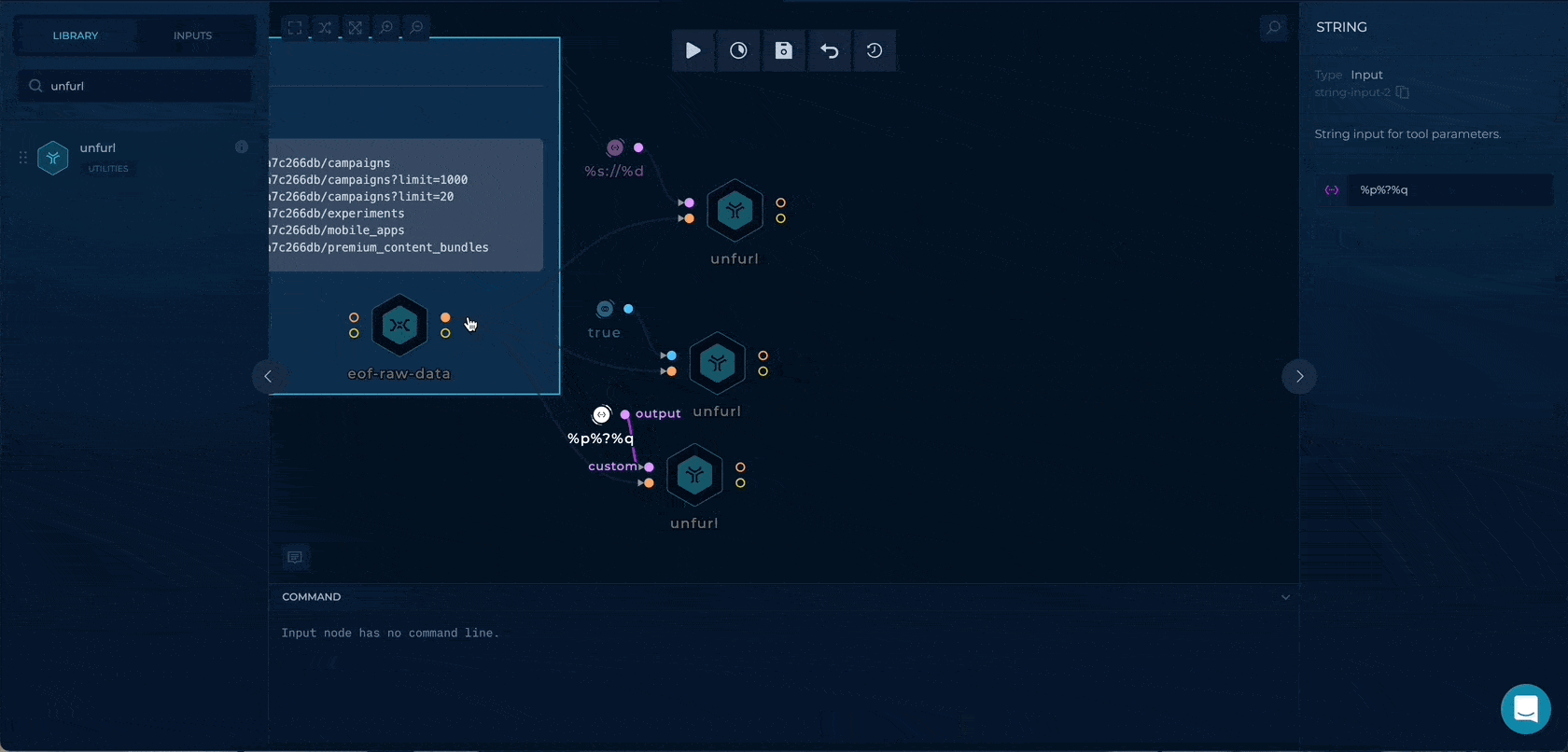
By dragging the cat-all-in script node, we can merge the only paths and the paths with query strings together, and by using the cut -c2- first character / will be deleted to format the wordlist.
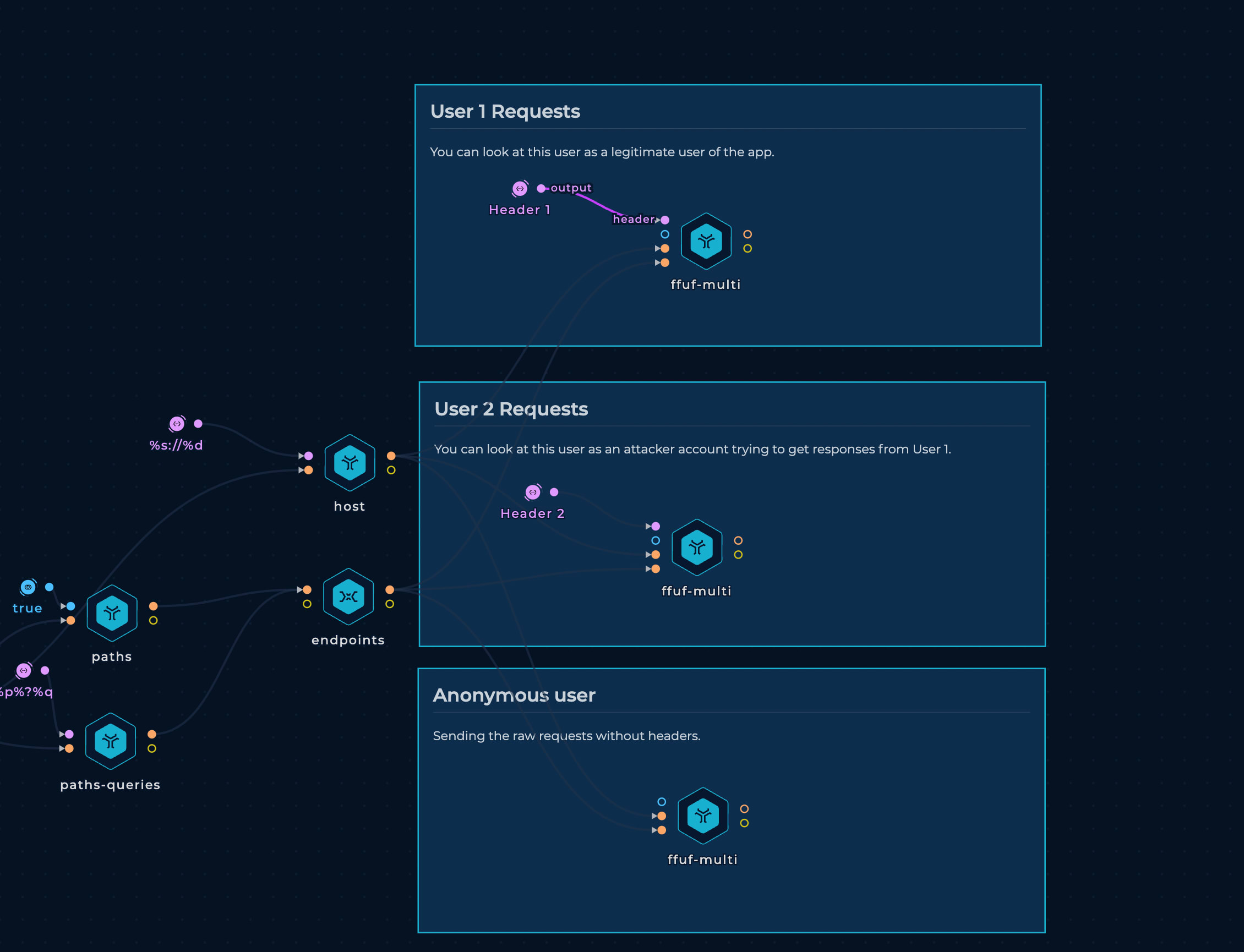
As we want to send the exact requests as different users, one of the ways when testing for IDOR vulnerabilities could be to request as a legitimate user, we call him User 1, with an attacker user, we can call it User 2 and anonymous user.
With this setup, three parallel instances of ffuf will be executed, but with different headers. When executing the workflow, headers should be replaced with the headers off appropriate users.
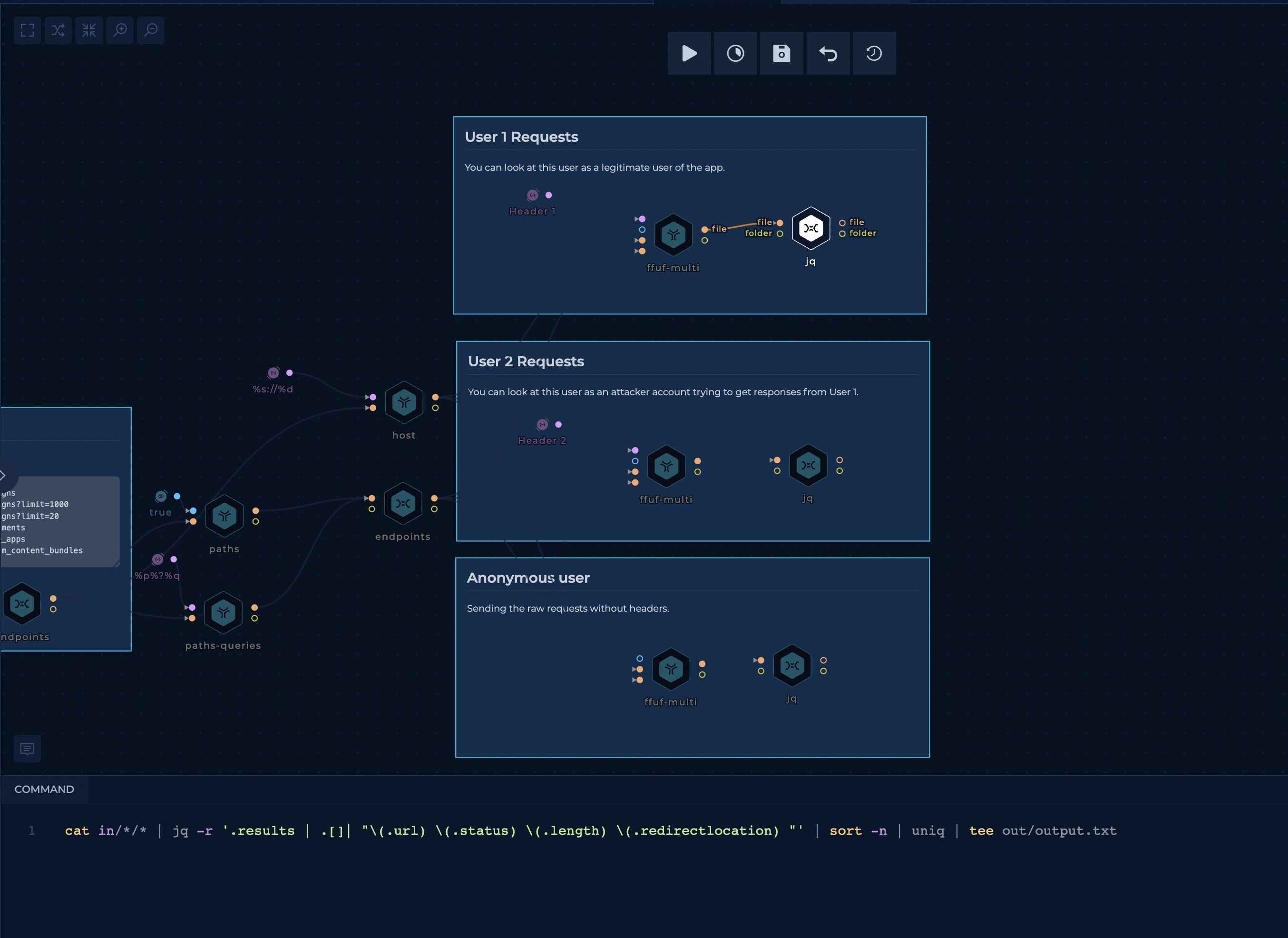
For now, we will only test for a status-code or content-length change.
This script will parse `ffuf's output to print out the URL, status and content-length.
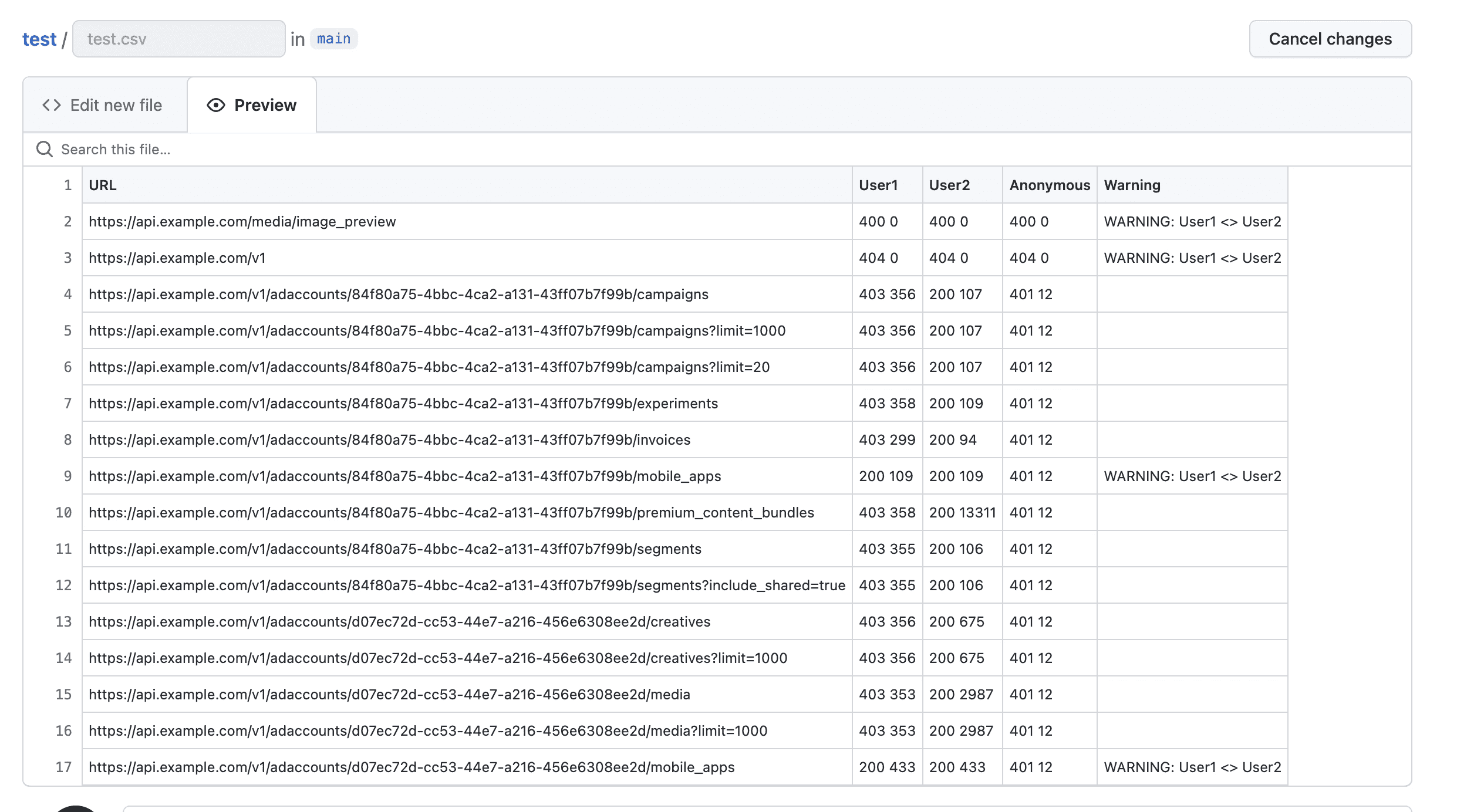
cat in/*/* | jq -r '.results | .[]| "\(.url) \(.status) \(.length) \(.redirectlocation) "' | sort -n | uniq | tee out/output.txtFinal result of a single ffuf output:
output.txt
https://api.example.com/v1 404 0
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/campaigns 401 12
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/campaigns?limit=1000 401 12
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/campaigns?limit=20 401 12
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/experiments 401 12
https://api.example.com/v1/adaccounts/55b7e66e-5219-5431-b909-5f6ca7c266db/mobile_apps 401 12
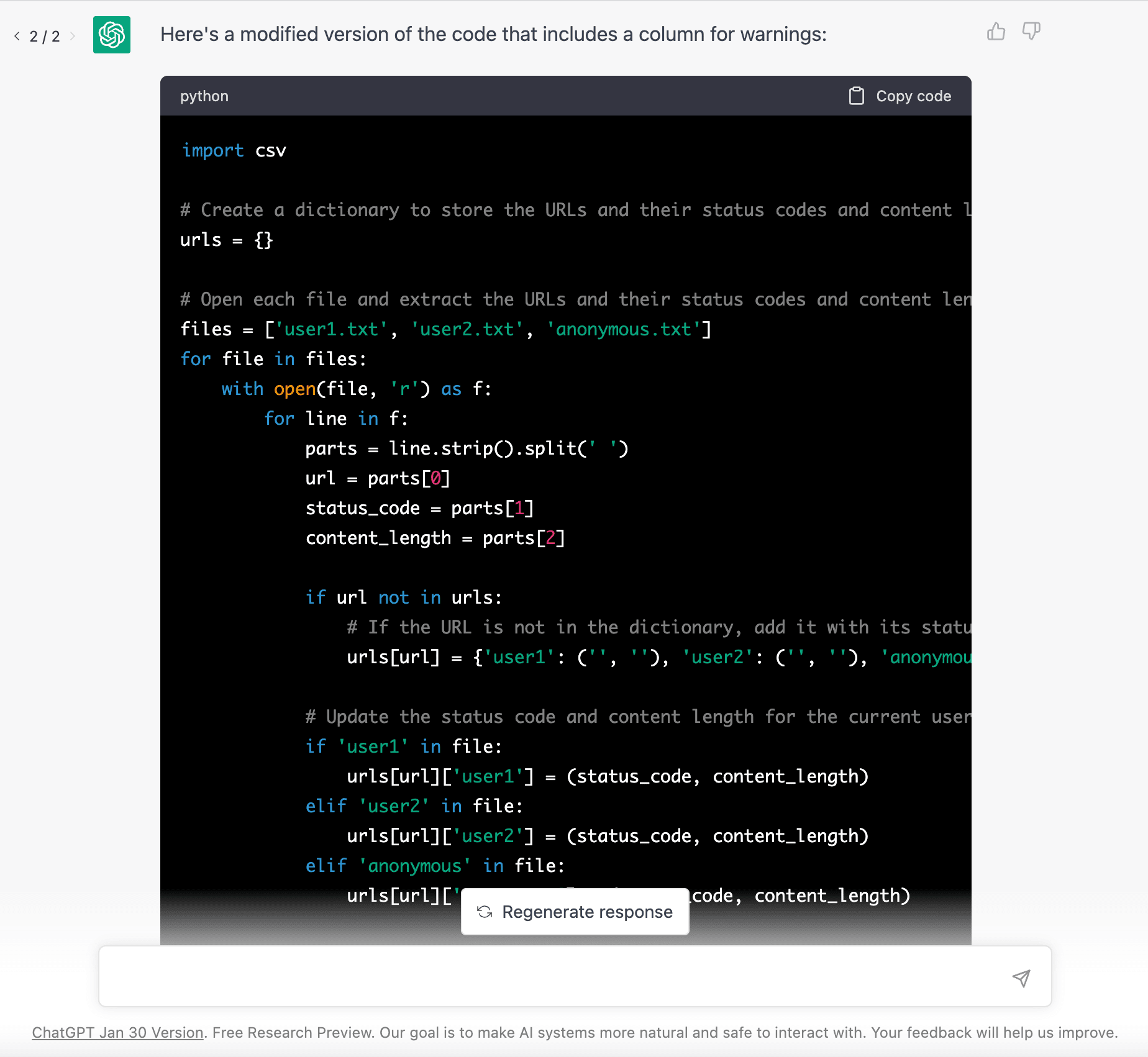
As we want to be quick, ChatGPT could help us here a lot. We provide it with the sample data and ask for a python script with an exact output.
We also asked it to compare the responses and to put WARNINGs where User1 and User2 have the same status-code and content-length.
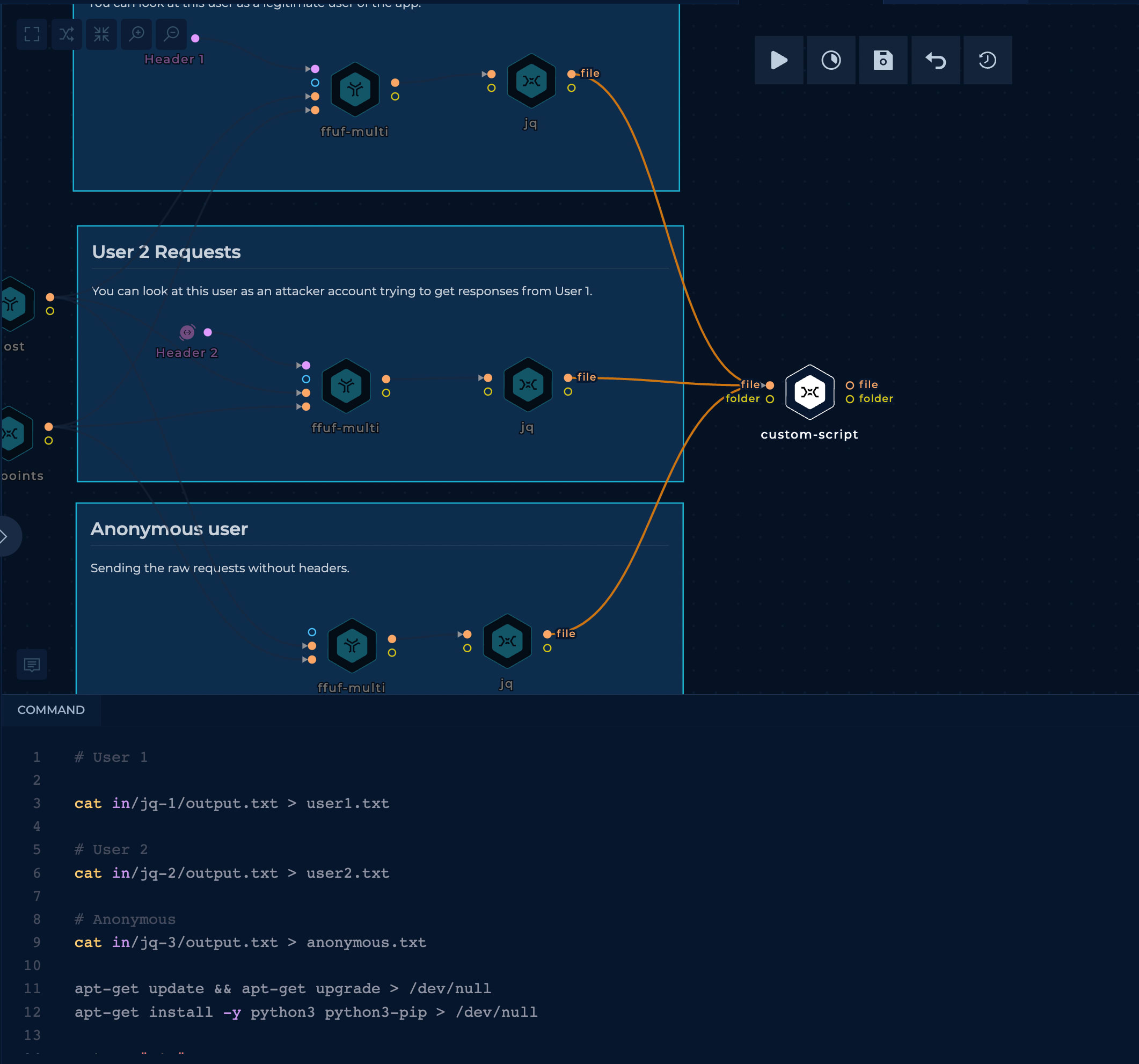
In the script nodes, we can firstly copy the files, install the python, paste the script and execute it at the end.
# User 1
cat in/jq-1/output.txt > user1.txt
# User 2
cat in/jq-2/output.txt > user2.txt
# Anonymous
cat in/jq-3/output.txt > anonymous.txt
apt-get update && apt-get upgrade > /dev/null
apt-get install -y python3 python3-pip > /dev/null
cat << "EOF" > compare.py
import csv
# Create a dictionary to store the URLs and their status codes and content length for each user
urls = {}
# Open each file and extract the URLs and their status codes and content length
files = ['user1.txt', 'user2.txt', 'anonymous.txt']
for file in files:
with open(file, 'r') as f:
for line in f:
parts = line.strip().split('')
url = parts[0]
status_code = parts[1]
content_length = parts[2]
if url not in urls:
# If the URL is not in the dictionary, add it with its status code and content length
urls[url] = {'user1': ('', ''), 'user2': ('', ''), 'anonymous': ('', '')}
# Update the status code and content length for the current user
if 'user1' in file:
urls[url]['user1'] = (status_code, content_length)
elif 'user2' in file:
urls[url]['user2'] = (status_code, content_length)
elif 'anonymous' in file:
urls[url]['anonymous'] = (status_code, content_length)
# Write the results to a CSV file
with open('out/output.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['URL', 'User1', 'User2', 'Anonymous', 'Warning'])
for url, values in urls.items():
user1_status_code, user1_content_length = values['user1']
user2_status_code, user2_content_length = values['user2']
anonymous_status_code, anonymous_content_length = values['anonymous']
if user1_status_code == user2_status_code and user1_content_length == user2_content_length:
writer.writerow([url, f'{user1_status_code} {user1_content_length}', f'{user2_status_code} {user2_content_length}', f'{anonymous_status_code} {anonymous_content_length}', 'WARNING: User1 <> User2'])
elif user1_status_code == anonymous_status_code and user1_content_length == anonymous_content_length:
writer.writerow([url, f'{user1_status_code} {user1_content_length}', f'{user2_status_code} {user2_content_length}', f'{anonymous_status_code} {anonymous_content_length}', 'WARNING: User1 <> Anonymous'])
elif user2_status_code == anonymous_status_code and user2_content_length == anonymous_content_length:
writer.writerow([url, f'{user1_status_code} {user1_content_length}', f'{user2_status_code} {user2_content_length}', f'{anonymous_status_code} {anonymous_content_length}', 'WARNING: User2 <> Anonymous'])
else:
writer.writerow([url, f'{user1_status_code} {user1_content_length}', f'{user2_status_code} {user2_content_length}', f'{anonymous_status_code} {anonymous_content_length}', ''])
EOF
python3 compare.pyNice! When the script is finished, it will output a CSV file that can be downloaded and used.
This workflow was made with as always, flexibility in mind. It should improve the pentester's productivity when testing to very specific and dangerous vulnerability affecting API endpoints.
The workflow could also be scheduled and configured to alert on differences. This way you can import the endpoints in your CI/CD and execute an IDOR testing workflow in a few clicks with trickest-cli and Trickest GitHub Action.
Some of the improvements of this workflow:
If you enjoyed this blog post and like the idea of automating your work, sign up to explore the platform and solutions.
Get a personalized demo
A 30-minute walkthrough. We map the platform to your stack and answer pricing and deployment questions for your environment.